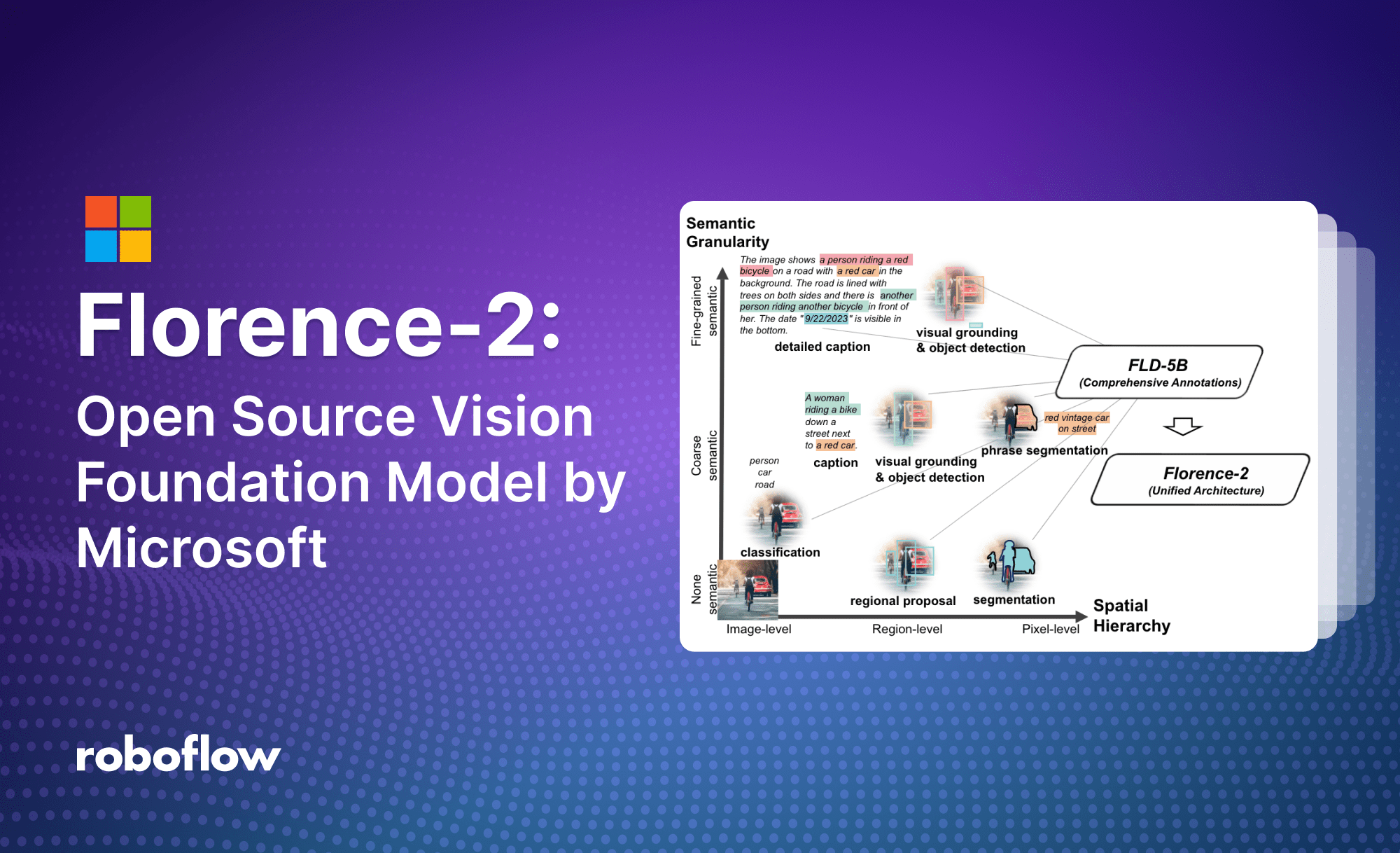
Florence-2 (Microsoft)開源模型 – 影像識別 (英)輕量級視覺語言模型模型在字幕、物件偵測、接地和分割等任務中展示了強大的零樣本和微調功能。 繼 Meta 推出多模態 open source 模型,Microsoft 也不甘後人,推出影像識別 Open source Florence-2 模型 儘管尺寸很小,但它所取得的結果與大許多倍的模型(如 Kosmos-2)相當。該模型的優勢不在於複雜的架構,而在於大規模的 FLD-5B 資料集,其中包含 1.26 億張影像和 54 億個綜合視覺註釋。