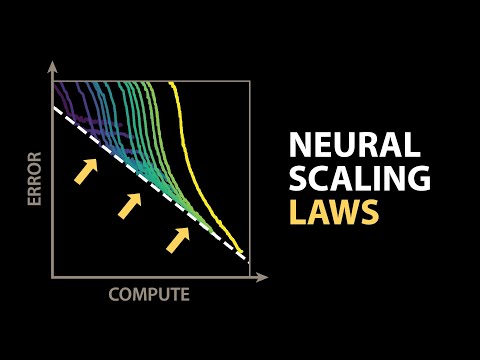
本片探討人工智慧模型效能的「神經網路縮放定律」。研究發現,模型的錯誤率與運算量、模型大小和數據集大小之間存在著冪律關係,這意味著效能提升遵循著簡單的數學規律,且與模型架構關係不大。OpenAI 和 DeepMind 的研究證實了此定律在廣泛的應用中成立,但模型效能最終會達到一個下限,這個下限與自然語言的本質熵有關。最後亦探討了「流形假設」,試圖從理論上解釋為何效能會遵循冪律關係,認為模型學習的高維數據空間中的低維流形,數據量和模型大小決定了模型對流形的解析度,從而影響效能。雖然理論與實驗結果有一定程度的吻合,但仍未能完全建立一套完整的AI理論。
AI can't cross this line and we don't know why.