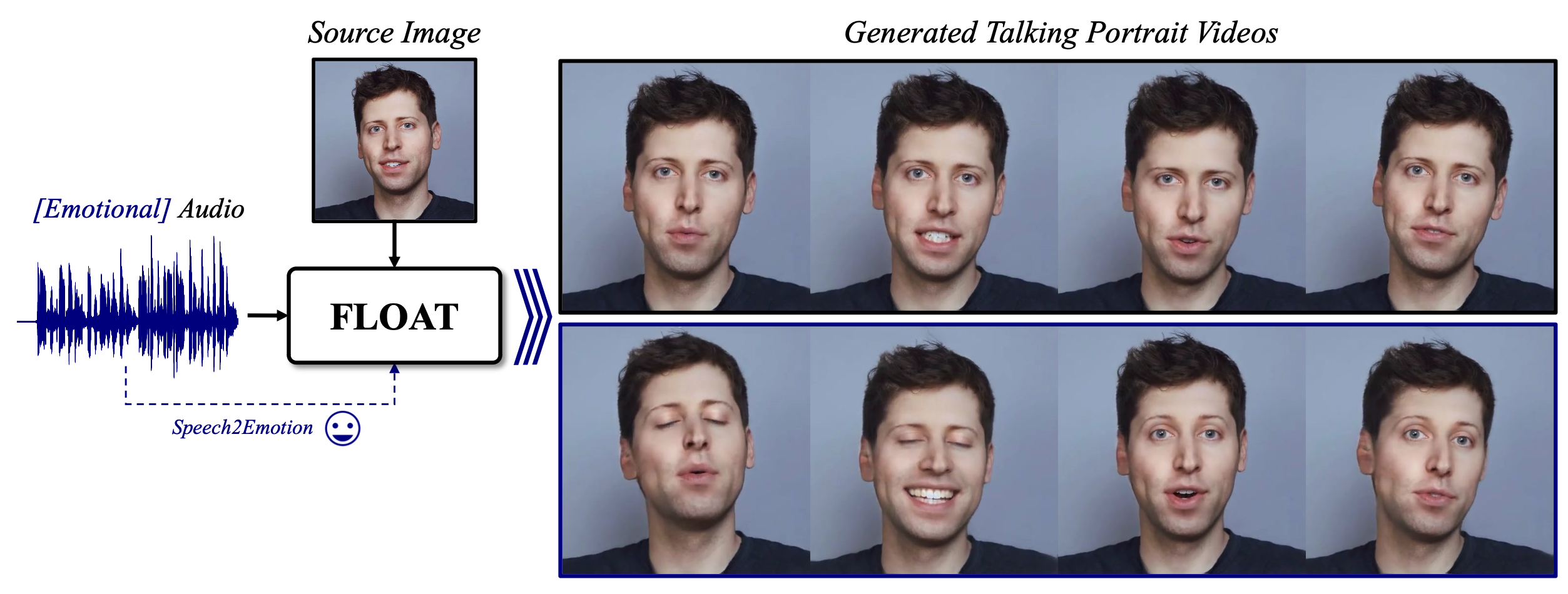
FLOAT 是個音訊驅動人像影片模型。模型提供能夠生成更自然、更具表現力的面部動畫,反映出說話者的情感狀態。
關鍵詞彙表
- 擴散模型 (Diffusion models): 一種生成模型,通過逐漸向數據添加噪聲,然後學習逆轉該過程來生成新數據。
- 流匹配 (Flow matching): 一種生成模型訓練技術,其目標是學習將簡單分佈轉換為目標數據分佈的變換。
- 運動潛在空間 (Motion latent space): 一個表示人像運動的低維空間,從輸入的人像圖像中學習得到。
- 音頻驅動說話人像生成 (Audio-driven talking portrait generation): 使用音頻信號作為輸入,生成與音頻同步的說話人像視頻的任務。
- 情感增強 (Emotion enhancement): 根據輸入的語音情感標籤,增強生成的人像動畫的情感表現力。
- 幀級 AdaLN (Frame-wise AdaLN): 一種自適應層歸一化技術,在每個時間步長根據條件信息調整特徵統計量,用於增強生成運動的多樣性。
- 函數評估次數 (NFEs): 評估生成模型所需的時間步長或迭代次數,用於衡量模型的效率。
- 3DMM 頭部姿態參數 (3DMM head pose parameters): 一種基於 3D Morphable Model 的人臉姿態表示,可以控制生成人像的頭部方向。