何謂 Text Embedding
Text Embedding(文本嵌入)是一種自然語言處理技術,用於將文本轉換成數值向量,保留其原始文本的意義和結構。這些向量被稱為Embeddings,它們可以用於許多NLP任務,如文本類似度計算、文本生成、文本分類等。 Text Embedding的目標是將文本轉換成一種可數學化的形式,使得它們能夠與其他數值向量進行比較和運算。這樣可以讓模型在處理文本時,能夠利用傳統的神經網路技術來進行分析和預測。 常見的Text Embedding方法包括: Word2Vec:是一種用於將單詞轉換成數值向量的方法,它通過訓練Word Embeddings模型來獲得每個單詞的向量表達。 GloVe:是一種基於矩陣分解的方法,旨在獲取每個單詞的向量表達,並利用文本中單詞之間的關聯信息來進行學習。 BERT(Bidirectional Encoder Representations from Transformers):是一種基於transformer架構的預訓練模型,它通過將文本轉換成向量表達,並且能夠捕捉到文本中的長距離依賴關係。 Text Embedding有許多應用,包括: 文本類似度計算:使用Embeddings可以比較兩個文本的相似程度。 文本分類:通過將文本轉換成向量表達,可以進行文本分類等NLP任務。 文本生成: Embeddings可以用於生成新的文本,例如文本摘要或文本完成。 4.推薦系統:使用Embeddings可以建構出基於文本的推薦系統。
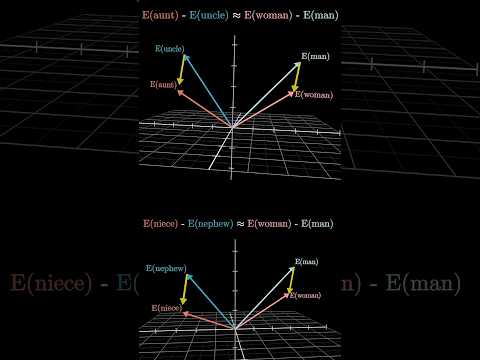
How word vectors encode meaning