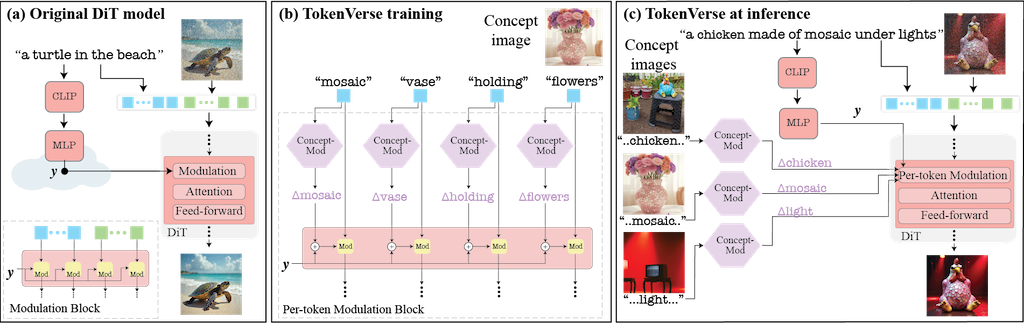
TokenVerse 提出一種基於預訓練文字轉圖像擴散模型的多概念個人化方法。它利用模型中的調製空間 (modulation space),從單張圖片中解開複雜的視覺元素和屬性,並能無縫地組合來自多張圖片的概念。不同於現有方法在概念類型或廣度上的限制,TokenVerse 能處理多張圖片的多種概念,包含物件、配件、材質、姿勢和光線等。核心方法是透過優化,為每個文字嵌入 (text embedding) 學習一個獨特的調製向量調整 (modulation vector adjustment),這些向量代表個人化的方向,可用於產生結合所需概念的新圖像。最後,論文展示了 TokenVerse 在具有挑戰性的個人化情境中的有效性,並突顯其優勢。