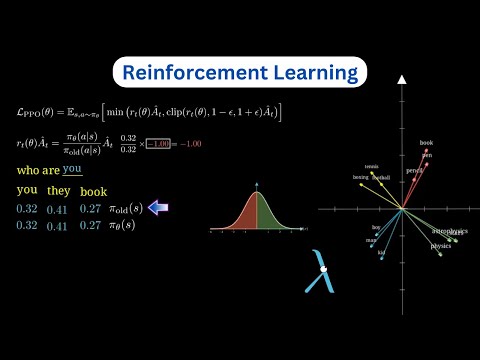
影片主要講解 DeepSeek R1 模型背後的強化學習演算法,並著重於如何透過人類回饋來訓練獎勵模型。包括如何根據人類對不同回應的偏好來調整獎勵值。接著深入探討 “近端策略優化”(Proximal Policy Optimization)演算法的細節。同時亦探討如何利用 “優勢函數”(Advantage Function)避免偏離原始策略。最後,影片亦解釋了如何運用群體策略優化成高於平均水準的回應,同時亦阻止了低於平均水準的回應,而因此提升了模型的推理能力。
Reinforcement Learning Behind DeepSeek-R1 visualized