它能利用兩個新的 Flux 模型(Flux Fill 和 Flux Redux)將衣服穿戴在人物模型上。能精準且智慧地將各種服飾,例如襯衫、褲子、鞋子、眼鏡和帽子等,甚至多件服飾同時,完美地套用到圖片中的人物身上,實現以往難以達成的穿衣效果。
REVOLUTIONIZE Online Shopping with FLUX's ComfyUi!

它能利用兩個新的 Flux 模型(Flux Fill 和 Flux Redux)將衣服穿戴在人物模型上。能精準且智慧地將各種服飾,例如襯衫、褲子、鞋子、眼鏡和帽子等,甚至多件服飾同時,完美地套用到圖片中的人物身上,實現以往難以達成的穿衣效果。
影片作者 Mickmumpitz 展示如何利用 ComfyUI,以及幾個開源 AI 影像模型 (例如 Co video x, LTX Video, Machi 1, Hyan),將自家拍攝的影片轉化成具有電影感的史詩級畫面。影片重點在於如何使用這個 AI 工作流程,包含設定、模型選擇 (不同模型各有速度與畫質的優劣)以及控制網路 (Control Net) 的應用,以達到精準控制影像生成的目標,例如保留演員表情和動作,或轉換角色外貌。影片也提供免費及付費兩種工作流程,付費版本提供更進階的功能,例如臉部替換和更精細的畫面調整。最後,作者展示了一部以這個方法製作的短片,說明其應用實例。
![Shoot EPIC MOVIES with this FREE AI Tool! [ComfyUI Tutorial + Free Workflow]](https://infer.store/wp-content/plugins/wp-youtube-lyte/lyteCache.php?origThumbUrl=https%3A%2F%2Fi.ytimg.com%2Fvi%2FgHI6PjTkBF4%2F0.jpg)
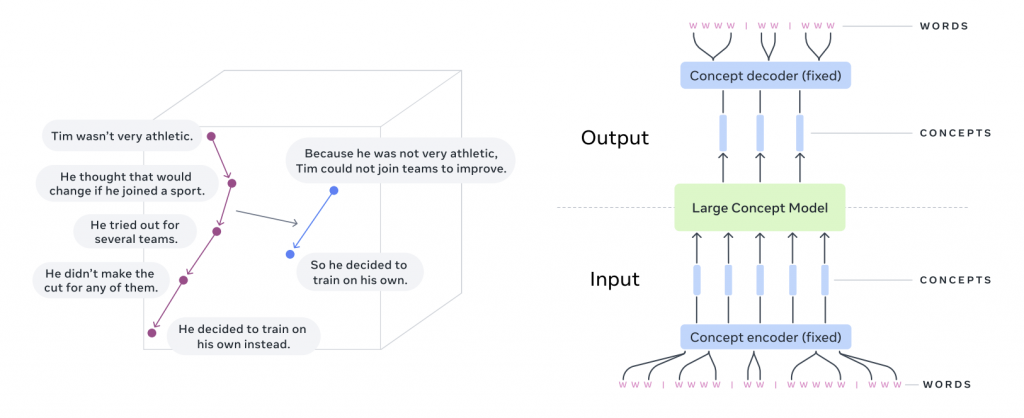
突破傳統以單詞為單位的 LLM,LCM(Large Concept Model) 直接處理句子級別的語義表示,即「概念」。研究人員利用 SONAR 嵌入空間,訓練 LCM 進行句子預測,並探索了多種模型架構和訓練方法,最終在 1.6B 和 7B 參數規模的模型上取得了優異的多語言零樣本泛化能力,尤其在摘要和摘要擴展任務上表現突出。 該研究成果及程式碼皆已公開釋出。
Jepa (Joint Embedding Predictive Architecture) 是一種在嵌入空間中預測下一個觀察表示的方法,V-JEPA (Video-JEPA) 是 Jepa 的一種伸延,加入影像作為一種自我監督的方式來學習影片的表示。

實戰:
更新包括:
🖊️ 頻道輸入指示器:準確了解誰在您的頻道中即時輸入,從而增強協作並保持每個人的參與。
👤 使用者狀態指示器:透過點擊頻道中的個人資料圖像來快速查看使用者的狀態,以獲得更好的協調和可用性見解。
🔒 可設定的 API 金鑰驗證限制:靈活配置 API 金鑰驗證的端點限制,現在預設為關閉,以便在受信任的環境中更順利地進行設定。


![]()
2017 年夏天,一群 Google Brain 研究人員悄悄發表了一篇將永遠改變人工智慧發展軌跡的論文。這份 “注意力就是你所需要的一切” (Attention Is All You Need) 的學術論文。當時人工智慧研究界之外很少有人知道這一點,但這篇論文將為你今天聽說過的幾乎所有主要生成式人工智慧模型奠定基礎,從 OpenAI 的 GPT 到 Meta 的 LLaMA 變體、BERT、 Claude、Bard 等。
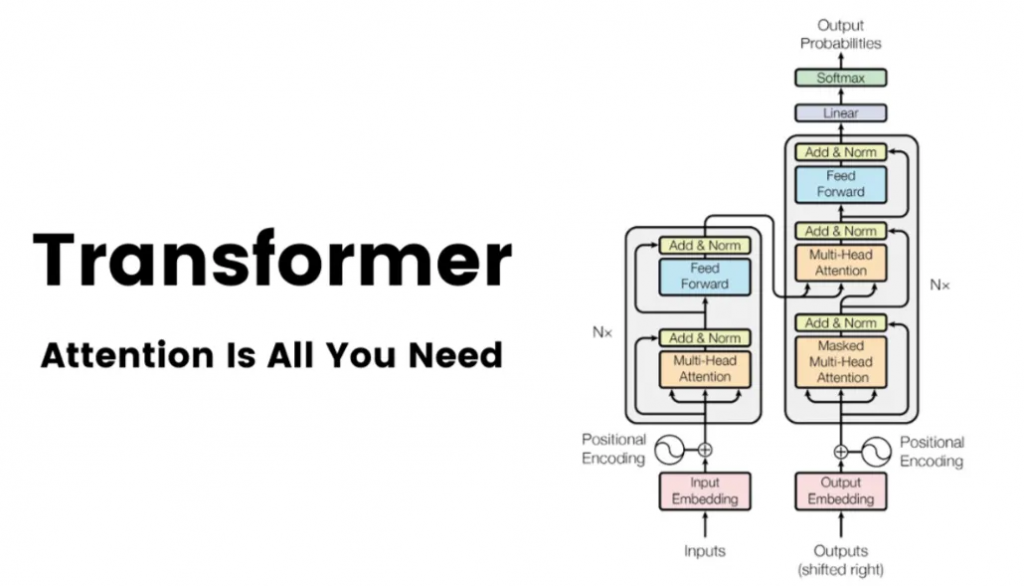
新的架構於 2020 年已經出現,例如 Performer、Longformer 和 Reformer,旨在提高超長序列的注意力效率。目前其他人正在嘗試混合方法,將 Transformer 區塊與其他專用層結合。這個領域絕非停滯不前。展望未來,每一項新提案都將受到審查、興奮,甚至恐懼。
一文搞懂 Transformer(總體架構 & 三種注意力層)
SwirlAI 電子報發表了一篇教學文章,旨在從零開始構建一個 AI 代理程式,無需任何框架。文章的核心在於說明如何讓 AI 代理程式使用工具 (Tools),並以一個貨幣轉換器為例,逐步演示整個過程。 作者首先定義了什麼是 AI 代理程式,並強調了系統提示 (system prompt) 的重要性,它包含了工具的定義和預期的輸出格式。文章亦詳細介紹了如何將 Python 函數包裝成工具,以及如何構造有效的系統提示,最後實現了一個能夠規劃並執行動作的 AI 代理程式類別,展示了如何讓 AI 代理程式根據用戶提問,自動選擇並使用工具完成任務。整個過程強調了基礎概念的理解,而非依賴現有框架。
騰訊開源模型 Hunyuan (混元) 能生成高品質 AI 影片,具有出色的動作穩定性、場景切換和逼真的視覺效果。ComfyUI 官網介紹了如何免費使用「Hunyuan Video」模型首先必需安裝幾個主要檔案:
hunyuan_video_t2v_720p_bf16.safetensors (主要的影片生成模型) 放入 -> ComfyUI/models/diffusion_models/ clip_l.safetensors 放入 -> ComfyUI/models/text_encoders/llava_llama3_fp8_scaled.safetensors (文字編碼器) 放入 -> ComfyUI/models/text_encoders/hunyuan_video_vae_bf16.safetensors (變分自動編碼器 VAE) 放入 -> ComfyUI/models/vae/模型亦支援生成靜態圖片,只需將影片長度設定為 1 即可。最後亦提供了一個 JSON 格式的工作流程範例,方便使用者快速上手。

Odyssey 公司開發的「Explorer」,一個能將圖片轉換成逼真三維世界的生成式世界模型,強調「故事至上」的理念,如同 Pixar 的成功經驗,科技應服務於故事和說故事的人。Explorer 利用高斯點雲 (gaussian splats) 技術建構細節豐富的場景,並能與現有 3D 創作軟體整合,實現手動編輯的功能。目前 Explorer 應用於電影、遊戲製作的虛擬製作流程中,未來目標是實現即時世界生成,並拓展更多應用,文中也提及與 Pixar 共同創辦人 Ed Catmull 的合作,突顯其在該領域的領先地位和遠大抱負。


