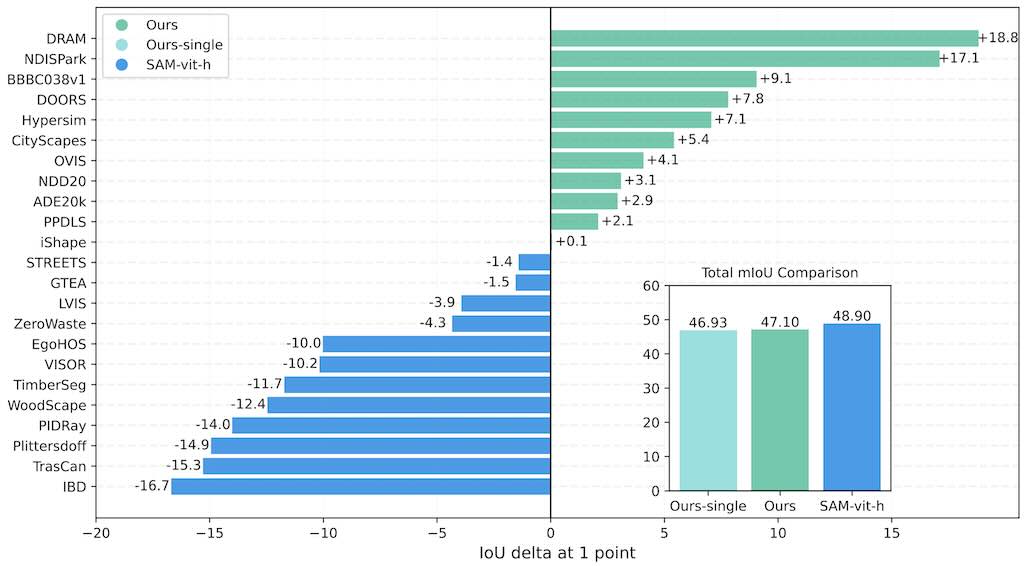
DICEPTION 是一個新型的通用擴散模型,是特別為影像的認知而設計。它只需要少量資料就能夠執行多種不同的影像偵察任務,例如距離的深度評估、畫面物件分類和評估人類身體的姿態。相對其他先進的擴散模型, 例如 SAM-vit-h Segment Anything Model,DICEPTION 只需用 0.06% 的數據就能夠展現出非常準確的成果。

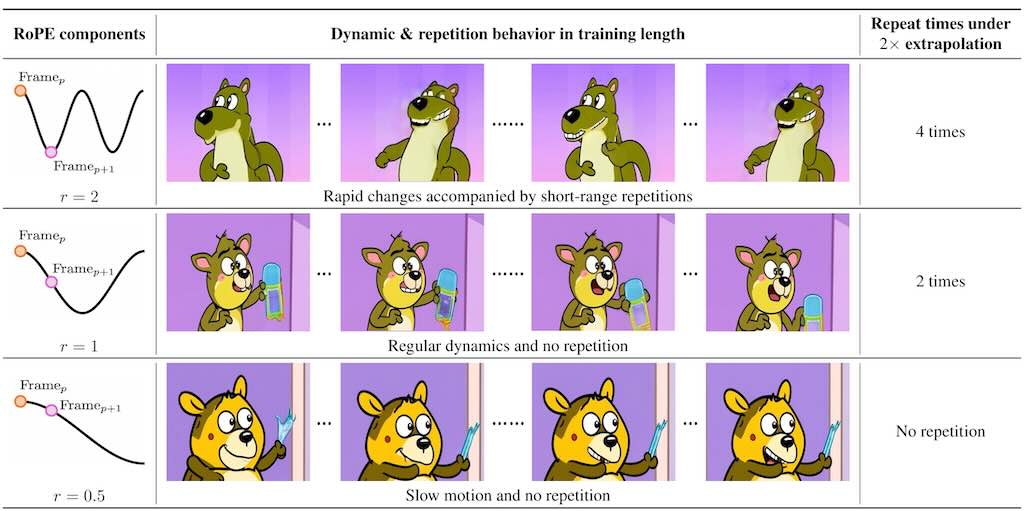
RIFLEx 主要延長影片的長度而無需重新訓練模型。研究發現,影片中不同頻率組成的部分會影響影片連貫性。在高頻會導致畫面重複,而低頻就會導致影片變成慢動作。RIFLEx 的方法是通過降低影片內在頻率,避免延長時候的重複問題,實現高品質的影片長度伸延。甚至能夠同時進行時間和空間的擴展。

影片主要講解 DeepSeek R1 模型背後的強化學習演算法,並著重於如何透過人類回饋來訓練獎勵模型。包括如何根據人類對不同回應的偏好來調整獎勵值。接著深入探討 “近端策略優化”(Proximal Policy Optimization)演算法的細節。同時亦探討如何利用 “優勢函數”(Advantage Function)避免偏離原始策略。最後,影片亦解釋了如何運用群體策略優化成高於平均水準的回應,同時亦阻止了低於平均水準的回應,而因此提升了模型的推理能力。
谷歌的 Titans 架構靈感來自人類記憶方式,包括短期、長期和持久記憶。Titans 的長期記憶能夠主動搵出相關資訊及時更新,而持久記憶就可以儲存推理技能,因此能夠擴展前文後理,並且能夠保持高準確性。

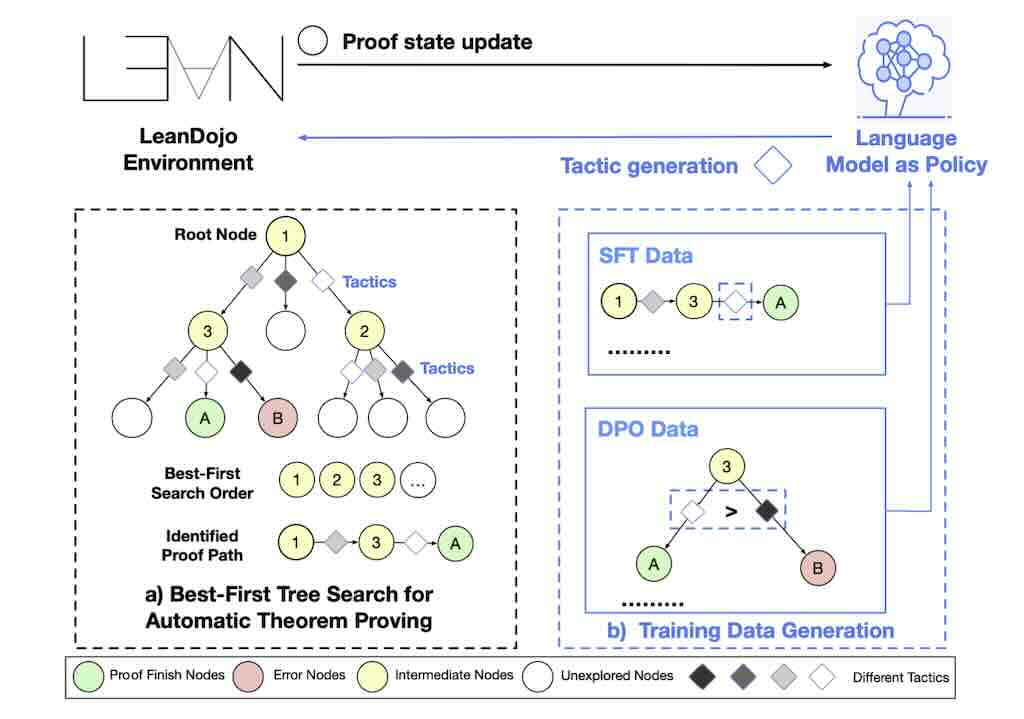
最佳優先搜尋 (BFS Best-First Tree Search) 是一種樹狀搜尋演算法,它透過優先從機率最高的節點來運作,屬於簡單和效率演算法,但普遍認為對於證明定理並不是最理想的方法。 BFS-Prover 挑戰了傳統觀點,
提出一種可擴展的專家疊代框架,主要包含了三個創新點:一是策略性數據過濾,二是利用編譯回饋進行直接偏好優化 (DPO) Direct Preference Optimization,三是長度正規化。
影片主要探討多模態嵌入模型 (Multimodal Embedding Models) 與檢索增強生成 (Retrieval-Augmented Generation, RAG) 的應用。作者討論了 Voyage AI 的多模態嵌入模型,並強調模型能有效地將圖像與文字等多種模態的資料整合到同一的嵌入空間,由於傳統的 CLIP 模型在多模態檢索和 RAG 應用中存在模態差距等問題,而 Voyage AI 可以直接將不同模態的資料轉換為 tokens 並輸入 Transformer 編碼器,解決了這些限制。

Google PaliGemma 2 mix 是 Gemma 系列中的一個升級版視覺語言模型,能夠處理多種任務。PaliGemma 2 mix 能夠直接用於大部份常見的場景,提供了不同大小的模型,分別為(3B、10B 和 28B 參數),解析度亦有兩種模式,分別是(224 和 448 像數)。模型擅長處理短文和長文的生成、光學字符識別、影像問答、物件偵測和影像分割等任務,並且可以搭配 Hugging Face Transformers、Keras、PyTorch、JAX 和Gemma.cpp 等工具使用。


透過 Gemini 2.0 API 和 Next.js 框架,作者分享了如何建構一個實時多模態應用程式。佢能夠接收影像和語音輸入,並透過 WebSocket 傳送至 Gemini API。Gemini API 會生成音頻輸出和文字轉錄,然後整合到有互動功能的聊天介面。教學包括深入探討應用程式的各個組件部分,例如媒體擷取、音訊處理、WebSocket 連線、轉錄服務以及用戶介面的更新。作者亦提供了開源的程式範例,並且逐步加以說明,方便大家由 GitHub 複製,並執行這應用程式。


