DeepRAG 的框架旨在解決大型語言模型(LLMs)在事實性知識上的不足,特別是它們容易產生幻覺的問題。DeepRAG 的核心思想是將檢索增強生成(RAG)視為一個馬可夫決策過程(MDP),使其能夠更策略性地進行檢索。透過分解式查詢,DeepRAG 可以動態決定是否要檢索外部知識或依賴模型自身的參數化推理,最終提升檢索效率和答案準確性。文中包含相關研究推薦、引用模型/數據集/Spaces 的情況以及論文收藏數量等資訊。

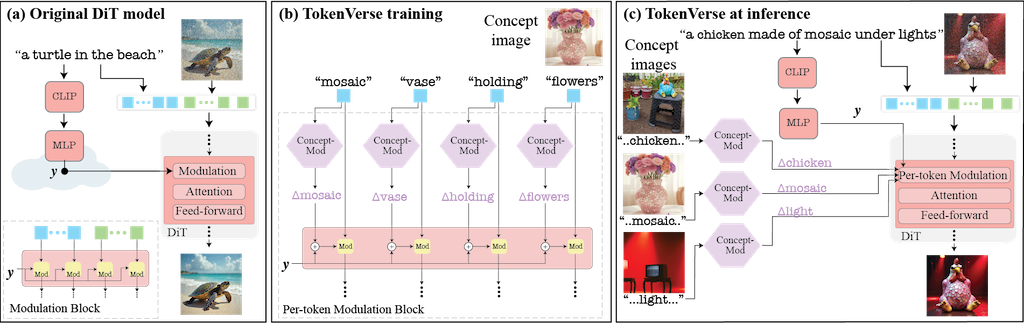
TokenVerse 提出一種基於預訓練文字轉圖像擴散模型的多概念個人化方法。它利用模型中的調製空間 (modulation space),從單張圖片中解開複雜的視覺元素和屬性,並能無縫地組合來自多張圖片的概念。不同於現有方法在概念類型或廣度上的限制,TokenVerse 能處理多張圖片的多種概念,包含物件、配件、材質、姿勢和光線等。核心方法是透過優化,為每個文字嵌入 (text embedding) 學習一個獨特的調製向量調整 (modulation vector adjustment),這些向量代表個人化的方向,可用於產生結合所需概念的新圖像。最後,論文展示了 TokenVerse 在具有挑戰性的個人化情境中的有效性,並突顯其優勢。
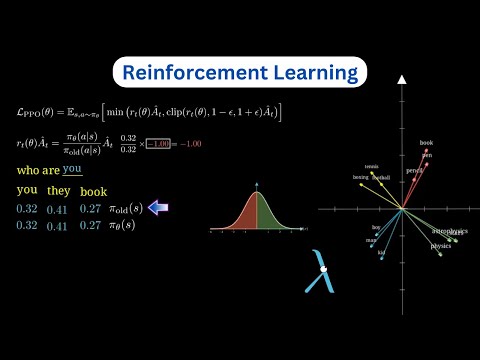
短片闡述 DeepSeek R1 模型的訓練過程,核心是基於人類回饋的強化學習。首先,短片解釋如何利用人類偏好訓練獎勵模型 (reward model):收集人類對不同模型輸出的評分,透過例如 Softmax 函數和梯階降法,調整獎勵模型,使其給予人類偏好的輸出更高分數。短片亦說明如何使用近端策略最佳化 (PPO) 演算法,結合獎勵模型和價值模型 (value model) 來微調語言模型 (policy network):根據獎勵模型給出的獎勵,以及評價模型預測的獎勵與預期差異 (advantage),調整策略網絡,使其更傾向產生高獎勵的輸出。最後,短片特別介紹 DeepSeek R1 使用的群體相對策略最佳化 (group relative policy optimization),這是一種改良的 PPO 方法,將獎勵與群體內其他輸出的平均獎勵相比,鼓勵產生優於平均水準的輸出,解決了傳統獎勵模型可能出現的「獎勵作弊」問題。
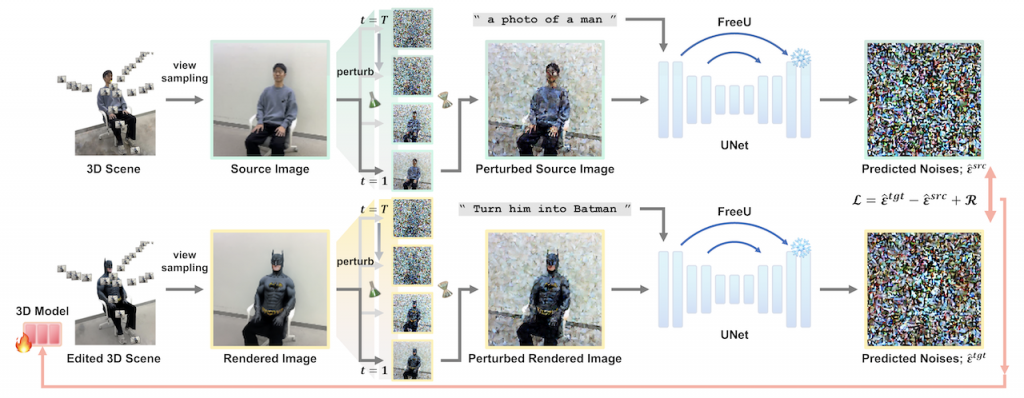
DreamCatalyst 是一個新穎的三維編輯架構,它改進了現有基於分數蒸餾採樣(SDS) 的方法,解決了訓練時間長和結果品質低的問題。DreamCatalyst 的關鍵在於將 SDS 視為三維編輯的擴散逆向過程,而不像現有方法那樣單純地蒸餾分數函數,使得更好地與擴散模型的採樣動態相協調。結果,DreamCatalyst 大幅縮短了訓練時間,並提升編輯品質,在速度和品質上都超越現有最先進的神經輻射場(NeRF) 和三維高斯散點(3DGS) 編輯方法,展現其快速且高品質的三維編輯能力。
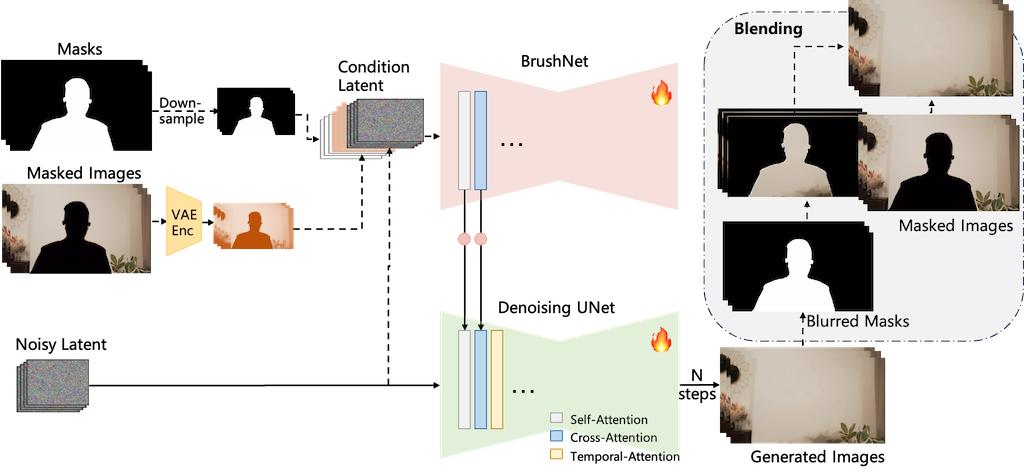
DiffuEraser 是個基於穩定擴散模型的開源影片修復模型。利用先驗資訊作為初始化,減少雜訊和幻覺,並藉由擴展時間以及利用影片擴散模型的時間平滑特性,提升長序列推論中的時間一致性。 DiffuEraser 透過結合鄰近影格資訊修復遮罩區域,展現比現有技術更佳的內容完整性和時間一致性,即使在處理複雜場景和長影片時也能產生細節豐富、結構完整且時間一致的結果,且無需文字提示。 其核心在於提升影片修復的生成能力與時間一致性。
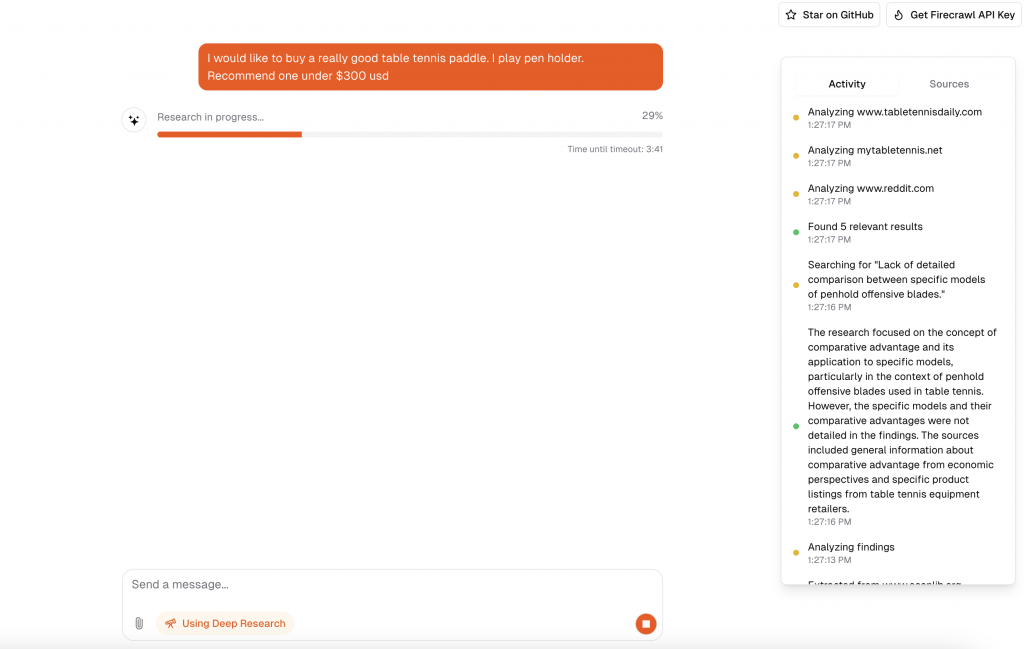
open-deep-research 是個開源的深度研究工具,模仿 OpenAI 的 Deep Research 實驗,但使用 Firecrawl 擷取和搜尋網頁資料,並結合推理模型,而非微調 o3 模型。 專案以Next.js建構,具有多種功能,包含即時資料饋送、結構化資料擷取、先進路由、支援多種大型語言模型(LLM)如 OpenAI、Anthropic 和 Cohere),當然亦 Support 免費的 Ollama 以及資料持久化機制。 提供本地部署和執行說明。 整體而言,它展示了一個強大的、可擴展的深度研究工具,並強調其開源和易於使用的特性。
這篇論文介紹了 DeepSeek 團隊開發的兩個大型語言模型:DeepSeek-R1-Zero 和 DeepSeek-R1,它們的核心目標是提升 LLM 的推理能力。DeepSeek-R1-Zero 利用大規模強化學習 (RL) 從頭訓練,展現出令人驚豔的推理能力,儘管存在可讀性和語言混雜等問題。DeepSeek-R1 則在 DeepSeek-R1-Zero的基礎上,加入多階段訓練和冷啟動數據,進一步提升效能,其推理能力已能與 OpenAI 的 o1-1217 模型相媲美。論文也展示了將DeepSeek-R1 的推理能力蒸餾到較小模型的成果,並公開釋出多個不同規模的模型,供研究社群使用。 論文詳細闡述了訓練方法、評估結果以及一些失敗的嘗試,為LLM推理能力的提升提供了寶貴的經驗和見解。
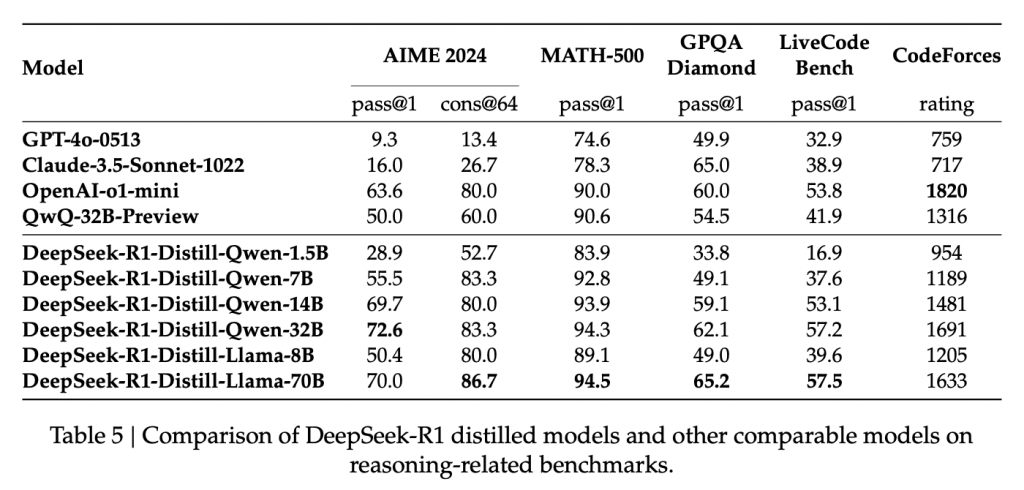
總結模型能力對比
DeepSeek-R1 在函數調用、多回合任務、複雜角色扮演以及 JSON 輸出等方面的能力優於 DeepSeek-V3。
未來研究方向
解決語言混合問題,目標是在未來解決這一限制。
提升提示工程的穩健性,建議用戶直接描述問題並使用零樣本設置指定輸出格式以獲得最佳效果。
探索利用 CoT(Chain-of-Thought)來增強這些領域的任務能力。
推理過程的挑戰
儘管 MCTS 與預訓練價值模型結合使用可以提高推理效率,但通過自我搜索迭代提升模型效能仍然是重大挑戰。
冷啓動強化學習
在冷啓動階段,利用檢查點收集數據並結合監督微調(SFT)來自其他領域的數據,增強模型在寫作、角色扮演和其他通用任務中的能力。
針對 CoT 在語言混合方面的問題,引入了語言一致性獎勵,以提高模型的性能。
涵蓋 DeepSeek-R1及其衍生模型(例如R10、R1Z)的全面介紹,包含安裝設定、效能基準測試(與OpenAI模型相比),以及各種硬體環境下的除錯和最佳化方法。課程重點在於如何有效利用 DeepSeek-R1 進行文本生成和圖像處理等 AI 任務,並強調模型優化和降低運算成本的重要性,同時展望了AI模型未來的發展趨勢。

Cherry Studio 是一款支持多個大語言模型(LLM)服務商的桌面客戶端,兼容 Windows、Mac 和 Linux 系統。支持主流 LLM 云服务:OpenAI、Gemini、Anthropic、硅基流动等。支持 Ollama 本地模型部署。内置 300+ 预配置 AI 助手。


![]()
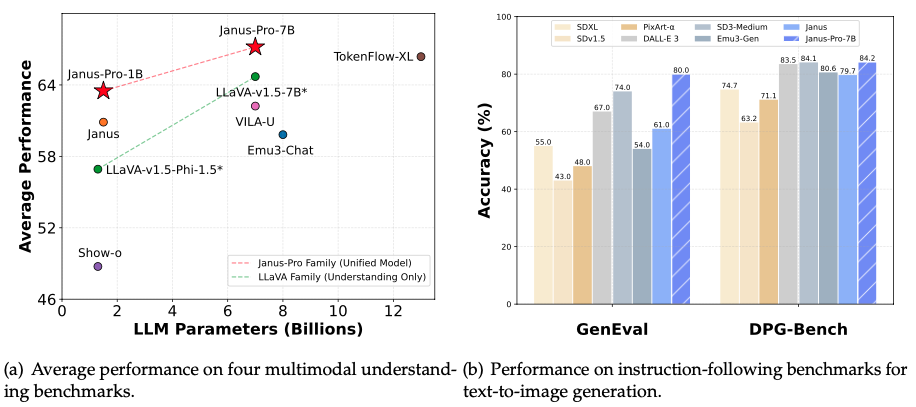
Janus 系列多模態理解和生成模型。核心是三個模型:Janus、Janus-Pro 和 JanusFlow,它們都基於單一 Transformer 架構,實現了統一的多模態理解和生成。Janus-Pro 是 Janus 的進階版,透過優化訓練策略、擴展數據和提升模型規模,顯著提升了性能。JanusFlow 則結合了自迴歸語言模型和修正流模型,在效能和多功能性上取得平衡。該資源提供了模型下載、快速入門指南,以及使用 Python 進行多模態理解和圖像生成的程式碼範例,並提供了 Hugging Face 線上演示和本地 Gradio/FastAPI 演示的說明。 最後,還列出了相關論文的引用資訊。