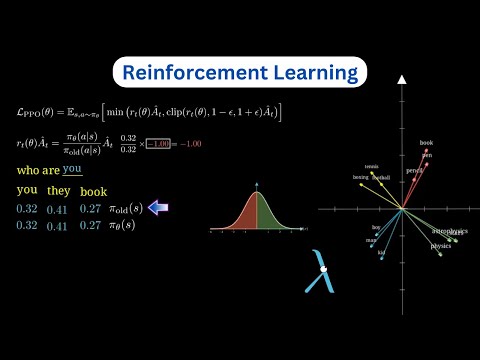
短片闡述 DeepSeek R1 模型的訓練過程,核心是基於人類回饋的強化學習。首先,短片解釋如何利用人類偏好訓練獎勵模型 (reward model):收集人類對不同模型輸出的評分,透過例如 Softmax 函數和梯階降法,調整獎勵模型,使其給予人類偏好的輸出更高分數。短片亦說明如何使用近端策略最佳化 (PPO) 演算法,結合獎勵模型和價值模型 (value model) 來微調語言模型 (policy network):根據獎勵模型給出的獎勵,以及評價模型預測的獎勵與預期差異 (advantage),調整策略網絡,使其更傾向產生高獎勵的輸出。最後,短片特別介紹 DeepSeek R1 使用的群體相對策略最佳化 (group relative policy optimization),這是一種改良的 PPO 方法,將獎勵與群體內其他輸出的平均獎勵相比,鼓勵產生優於平均水準的輸出,解決了傳統獎勵模型可能出現的「獎勵作弊」問題。
Reinforcement Learning in DeepSeek-R1 | Visually Explained