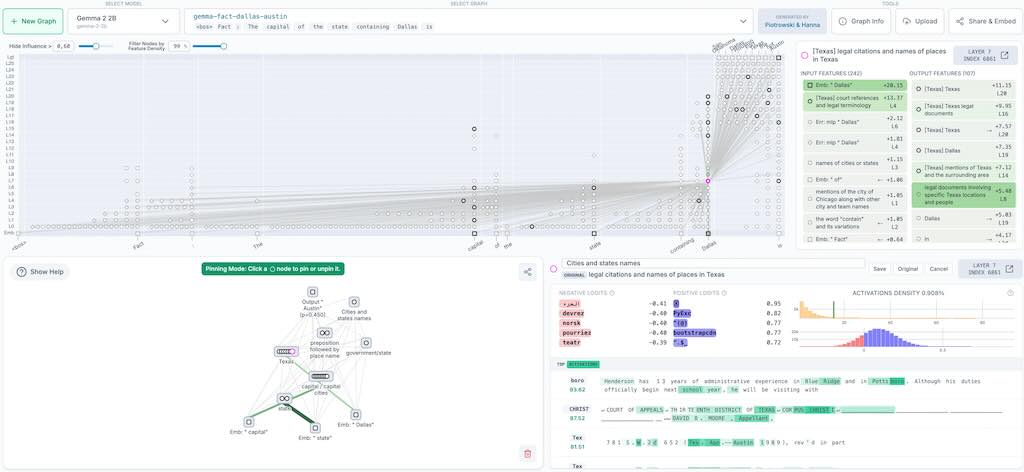
影片中,作者使用了 Google 的 embedding 模型和 ChromaDB 向量資料庫來實現這個架構。
- RAG 架構簡介 解釋了 RAG 的基本原理,即將長文章拆分成小片段,對每個片段進行 embedding,然後儲存到向量資料庫中,並在使用者提問時找出最相關的片段發送給大型語言模型。
- 文章分塊 示範如何將一篇關於「令狐沖轉生為史萊姆」的虛構文章進行分塊處理。他首先使用雙回車符作為切分依據,然後進一步優化,將以警號開頭的標題與後續的正文合併。
- Embedding 與資料庫儲存 介紹如何使用 Google 的 embedding 模型對分塊後的文本進行 embedding,並將這些 embedding 及其原始文本儲存到 ChromaDB 向量資料庫中。作者特別提到 Google embedding 模型的「儲存」和「查詢」兩種模式。
- 查詢功能 說明如何透過查詢 embedding 模型並從 ChromaDB 中檢索出與使用者問題最相關的文本片段。
- 整合大型語言模型 最後,展示如何將查詢到的相關文本片段與使用者問題一起發送給大型語言模型(Gemini Flash 2.5),以生成更準確的回應。
影片強調動手實作的重要性,鼓勵觀眾親自寫一遍程式碼以加深理解。
从零写AI RAG 个人知识库