FramePack 是一種新的視頻擴散設計,用壓縮上下文令工作量不會隨著影片的長度而增加,只需一張圖片,就可以令你的 6GB vRAM 的電腦透過 13B 模型生成每秒 30 格影片的 60 秒影片。而用 RTX 4090 的話,最快速度為每格 1.5 秒。
作者 Lvmin Zhang
FramePack Run In Gradio & ComfyUI - Generate Long Length image2Video AI Video - Installation Guide

FramePack 是一種新的視頻擴散設計,用壓縮上下文令工作量不會隨著影片的長度而增加,只需一張圖片,就可以令你的 6GB vRAM 的電腦透過 13B 模型生成每秒 30 格影片的 60 秒影片。而用 RTX 4090 的話,最快速度為每格 1.5 秒。
作者 Lvmin Zhang
Llama 4 Scout 是一個擁有 170 億個活躍參數和 16 個 MOE 的混合專家模型。它被認為是目前同類型最優秀的多模態模型,比前幾代的 Llama 模型更強大。新模型可以用單張 NVIDIA H100 GPU 運作。佢擁有業介領先的 1000 萬 tokens 上下文窗口,並且在廣泛使用的基準測試表現都優勝過 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1。它在預訓練和後訓練的過程都用了 256K 的上下文長度。
另一個模型 Maverick 同樣是一個擁有 170 億個活躍參數的模型,但它擁有 128 個 MOE 的混合專家模型。基準測試擊敗了 GPT-4o 和 Gemini 2.0 Flash,而在圖像方面亦表現相當出色,能夠將提示詞同埋相關的視覺概念對齊,將模型的回應鎖定到圖像中的特定區域。兩個模型都有獨特的活躍參數模式,能夠節省一半資源。令開發同應用的價格更低。


WhatsApp MCP 可利用您的個人 WhatsApp 帳戶進行搜索訊息、聯絡人及群組,並能向個人或群組發送訊息。所有訊息會自動儲存到本地的 S Q Lite 資料庫,確保私隱同控制權。用戶只需要掃描 QR code 就可以驗證帳戶並開始使用。WhatsApp MCP 整合了 Claude Desktop,利用語言模型來增強訊息的處理功能,十分適合需要高效管理 WhatsApp 通訊的用戶。
InfiniteYou 的獨特之處在於其強大的身份保留技術!透過核心組件 InfuseNet,即使在生成全新場景或是不同風格的相片,也能精準保留相片中的人物特徵。您可以僅以文字描述,就能讓同一人物出現在不同情境、穿著不同的衫,甚至呈現不同的風格。它亦支援 ControlNet 和 LoRA 的進階控制,令創意揮灑的同時,也能精細調整生成結果,直至符合您需要的獨特內容!(ByteDance)

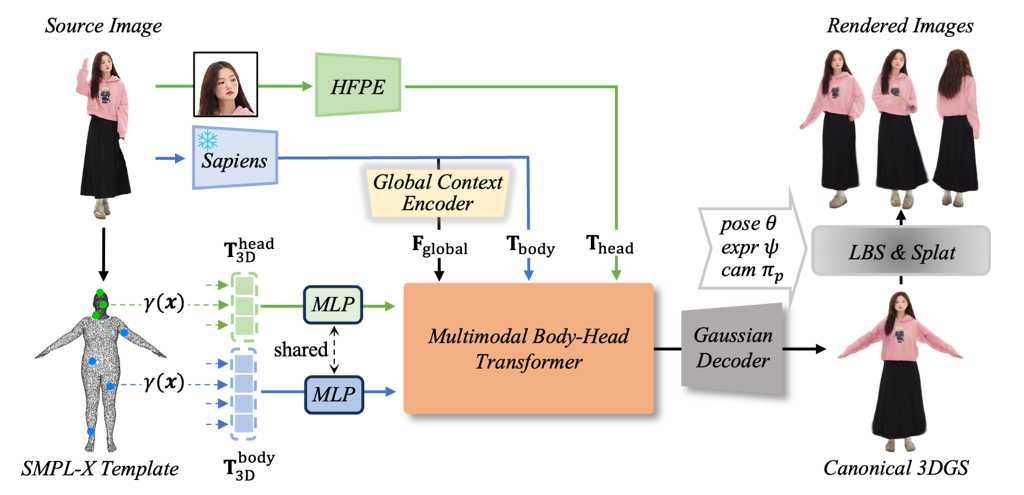
LHM (Large Animatable Human Reconstruction Model) 是一個高效及高質量的 3D 人體重建方案模型,能夠在幾秒鐘內生成影片。模型利用了多模態的 Transformer 架構,以注意力機制,對人體特徵和影像特徵進行編碼,能夠詳細保存服裝的幾何形狀和紋理。為了進一步增強細節,LHM 提出了一種針對頭部特徵的金字塔型編碼方案,能夠生成頭部區域的多種特徵。(阿里巴巴)
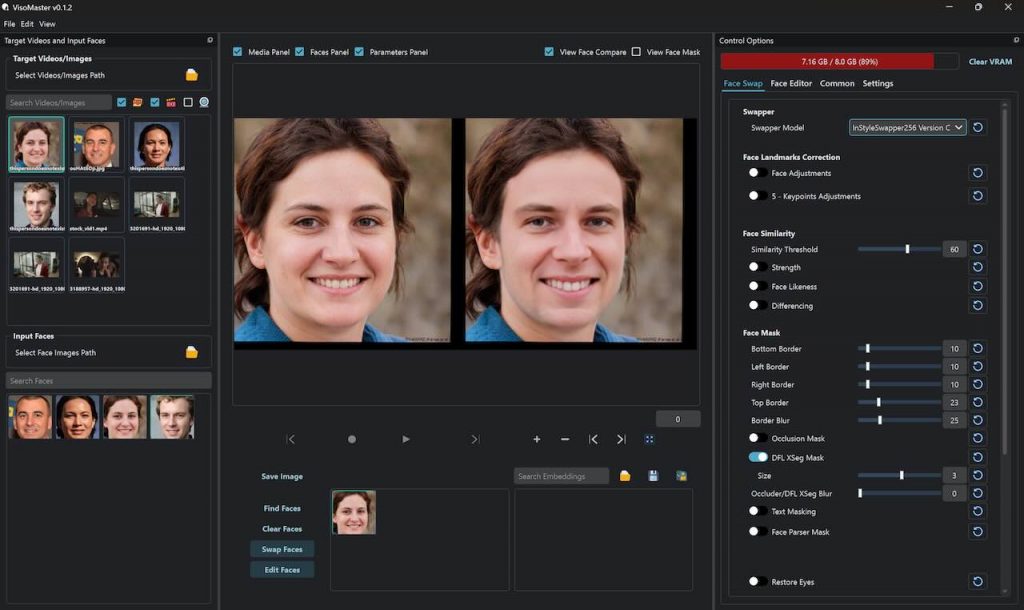
VisoMaster 是一個功能強大的面部替換與編輯工具,無論是靜態圖片還是動態影片,都能夠輕鬆地進行面部替換。替換後的結果非常自然流暢,幾乎看不出任何人工編輯的痕跡。而且可以根據需求定制模型和微調參數,以獲得更個性化的面部替換效果。

Qwen 2.5-Omni,是一個由阿里巴巴團隊開發的端對端多模態模型。它的主要目的是統一處理輸入的文字、圖像、音訊和影片,能同時生成文字和自然語音作為回應。模型在多模態輸入的感知、文字與語音的同步生成以及串流處理的優化等方面都採用了創新技術同埋架構,例如 TMRoPE 時間對齊編碼和 Thinker-Talker 架構。下面的影片詳細示範了 Qwen 在不同的應用場景下的優秀表現。


FlashVideo 由香港大學、香港科技大學及 ByteDance 聯合開發,你只需要準備一張或者幾張參考圖片,加上文字提示詞,就可以生成高解像度的影片。過程主要分為兩部份,第一部分是優先處理提示詞,同時以低解像度處理圖片,減少 DIT 的運算時間。第二部分會建立低解像度和高解像度之間的匹配。結果能夠以高速生成 1 0 8 0 P 的高清影片。[DiT] Diffusion Transformer | [NFE ] Number of Function Evaluations

NotaGen 針對160 萬首樂曲進行了訓練,亦根據高品質古典樂譜數據進行了微調。當中包括 8 千 948 張古典樂譜、152 位作曲家,並規劃成為巴洛克、古典及浪漫等三個時期。NotaGen 採用 CLaMP-DPO 強化學習,無需經過人工註釋甚至預先定義的獎勵。結果可以輕易生成非常出色的 Full Score 樂章節同埋五線譜樂章。

相關函式庫:DCML 語料庫、OpenScore 弦樂四重奏語料庫、OpenScore 歌曲語料庫、
ATEPP、KernScores



