2025 年 2 月 16 日,DeepSeek 提出了一種名為「原生稀疏注意力」(NSA)
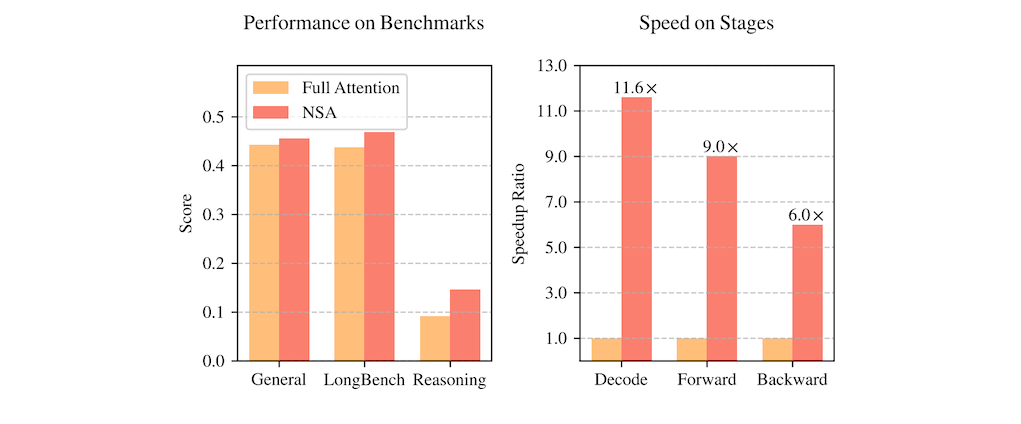
Natively trainable Sparse Attention 的新型注意力機制,目的是解決長傳統注意力機制運算量過大的問題。NSA 透過結合分層式 Token 壓縮與硬體加速設計,達成既能有效處理長文本,又不會顯著增加運算負擔的目標。其核心創新點在於演算法與硬體協同優化,保持甚至超越完整注意力模型的性能。實驗證明,NSA 在多項基準測試中表現出色,並且在解碼、前向傳播和反向傳播階段都顯著加速。
【人工智能】DeepSeek再发新研究成果NSA | 原生稀疏注意力机制 | 梁文锋参与 | 超快长上下文训练 | 十倍速度提升 | 动态分层 | 粗粒度压缩 | 细粒度选择 | 滑动窗口
