這篇論文介紹了 DeepSeek 團隊開發的兩個大型語言模型:DeepSeek-R1-Zero 和 DeepSeek-R1,它們的核心目標是提升 LLM 的推理能力。DeepSeek-R1-Zero 利用大規模強化學習 (RL) 從頭訓練,展現出令人驚豔的推理能力,儘管存在可讀性和語言混雜等問題。DeepSeek-R1 則在 DeepSeek-R1-Zero的基礎上,加入多階段訓練和冷啟動數據,進一步提升效能,其推理能力已能與 OpenAI 的 o1-1217 模型相媲美。論文也展示了將DeepSeek-R1 的推理能力蒸餾到較小模型的成果,並公開釋出多個不同規模的模型,供研究社群使用。 論文詳細闡述了訓練方法、評估結果以及一些失敗的嘗試,為LLM推理能力的提升提供了寶貴的經驗和見解。
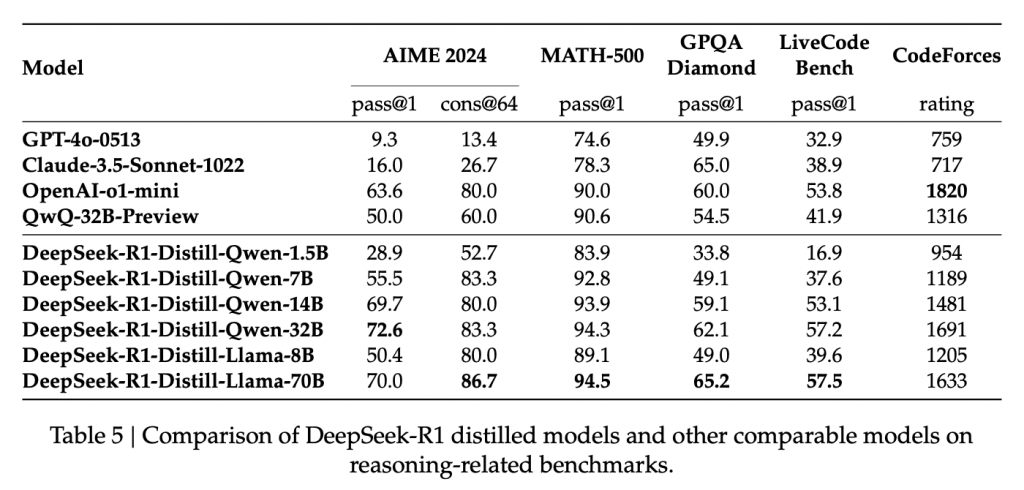
總結模型能力對比
DeepSeek-R1 在函數調用、多回合任務、複雜角色扮演以及 JSON 輸出等方面的能力優於 DeepSeek-V3。
未來研究方向
解決語言混合問題,目標是在未來解決這一限制。
提升提示工程的穩健性,建議用戶直接描述問題並使用零樣本設置指定輸出格式以獲得最佳效果。
探索利用 CoT(Chain-of-Thought)來增強這些領域的任務能力。
推理過程的挑戰
儘管 MCTS 與預訓練價值模型結合使用可以提高推理效率,但通過自我搜索迭代提升模型效能仍然是重大挑戰。
冷啓動強化學習
在冷啓動階段,利用檢查點收集數據並結合監督微調(SFT)來自其他領域的數據,增強模型在寫作、角色扮演和其他通用任務中的能力。
針對 CoT 在語言混合方面的問題,引入了語言一致性獎勵,以提高模型的性能。