DeepSeek-V3 的架構,包含創新的多標記預測 (MTP) 目標函數和無輔助損失的負載平衡策略,以及基於Multi-Head Latent Attention (MLA) 和 DeepSeekMoE 的高效能設計。
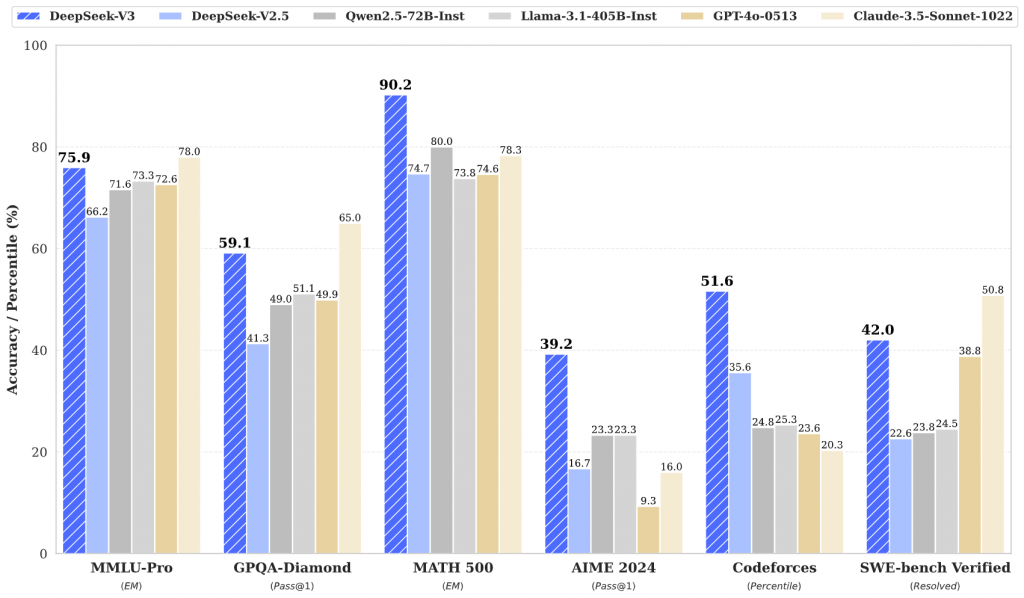
DeepSeek-V3 是一種強大的專家混合 (MoE) 語言模型,總參數為 671B,每個令牌啟動 37B。為了實現高效的推理和經濟高效的訓練,DeepSeek-V3 採用了多頭潛在註意力(MLA)和 DeepSeekMoE 架構,這些架構在 DeepSeek-V2 中得到了徹底的驗證。在 14.8 兆個多樣化的高品質 Token 上對 DeepSeek-V3 進行預訓練,然後進行監督微調和強化學習階段,以充分利用其能力。綜合評估表明,DeepSeek-V3 的性能優於其他開源模型,並且達到了與領先的閉源模型相當的性能。儘管性能出色,DeepSeek-V3 僅需要 2.788M H800 GPU 小時即可完成完整訓練。此外,它的訓練過程非常穩定。在整個訓練過程中,沒有遇到任何不可恢復的損失高峰或執行任何回滾。
【人工智能】DeepSeek V3 53页技术报告快速解读 | 性能表现卓越 | 架构创新 | MLA | MoE架构 | DualPipe | 预训练 | 超参数设置 | MTP | 后训练
