威斯康星 – 麥迪遜大學,微軟研究院,哥倫比亞大學的一群研究者發佈了LLaVA多模態大模型。LLaVA是一種新穎的端到端訓練的大型多模態模型,結合了視覺編碼器和Vicuna對於通用的視覺和語言理解, 實現令人印象深刻的聊天功能。
作者提供測試版 Demo,你可直接用手機測試。


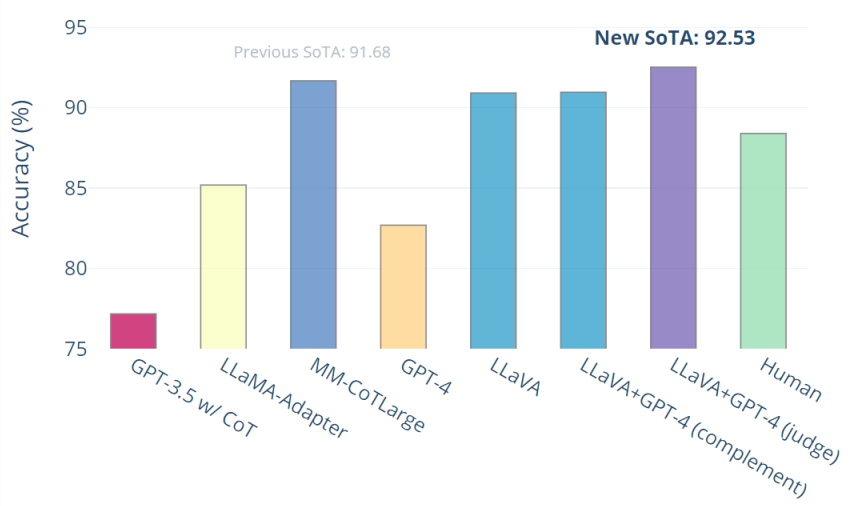
當對科學 QA 進行微調時,LLaVA 模仿多模式 GPT-4 的思想,在科學 QA 上實現了當前最先進的準確性。LLaVA 和 GPT-4 的協同作用達到了 92.53% 的新先進準確度。它最有意思的一點是,它利用了GPT-4來生成訓練數據。