快速文字引導影像編輯工具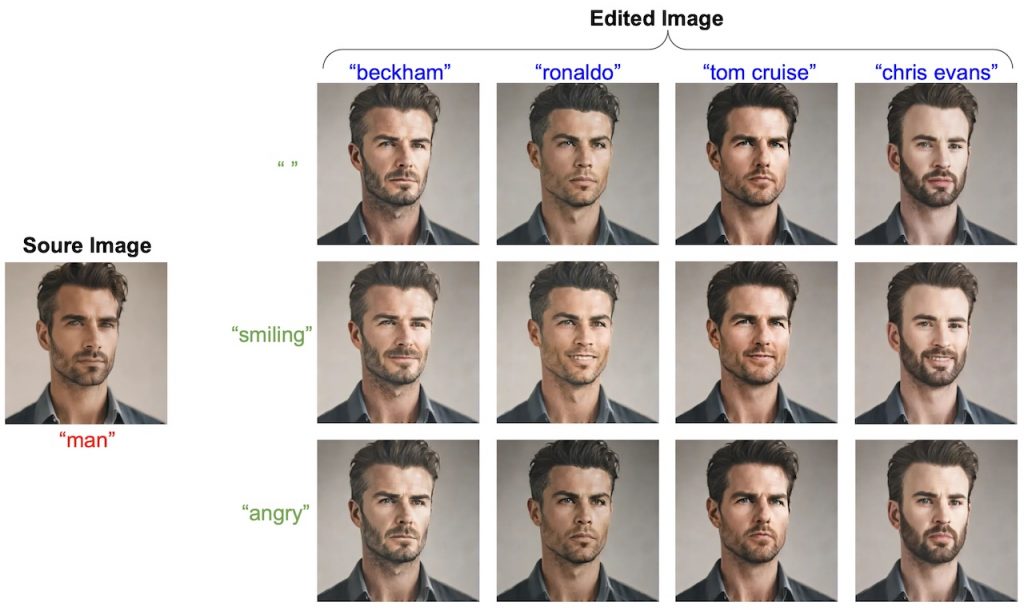
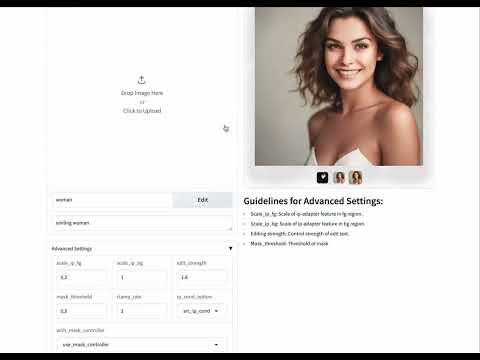
以0.23秒內完成影像編輯,比現有方法快至少50倍。SwiftEdit 的關鍵在於其一步到位反轉框架,能一步重建影像,以及遮罩引導的編輯技術,藉由注意力重新調整機制來進行局部編輯,同時保留背景細節。其雙階段訓練策略和自動提取編輯區域的機制,並透過範例展示其在人臉編輯和基準測試中的有效性和效率。 其目的在提供一個快速、使用者友善且高效的影像編輯工具。(暫未提供源碼)
Demo: SwiftEdit: Lightning Fast Text-guided Image Editing via One-step Diffusion