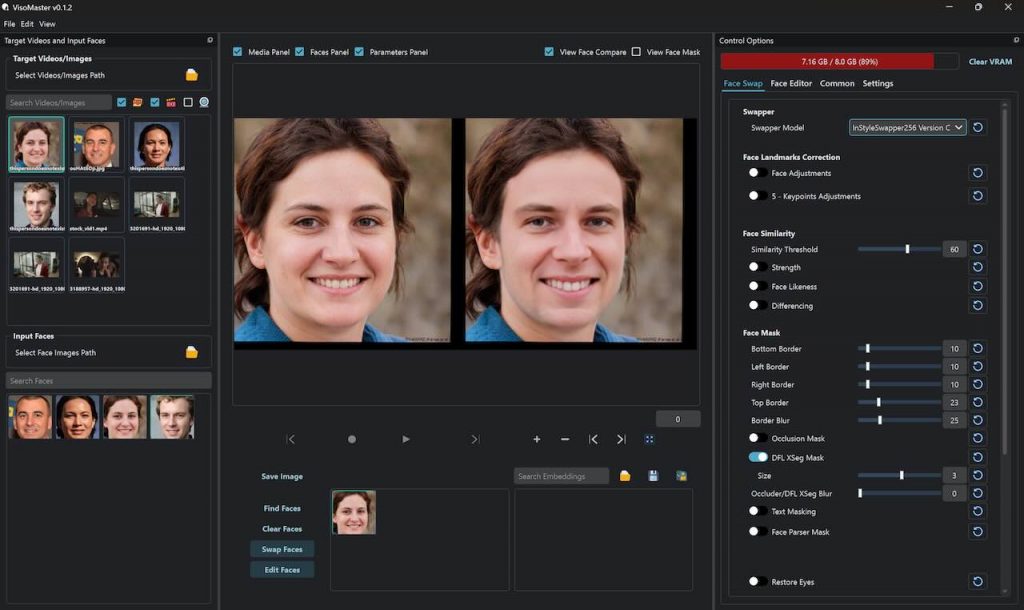
VisoMaster 是一個功能強大的面部替換與編輯工具,無論是靜態圖片還是動態影片,都能夠輕鬆地進行面部替換。替換後的結果非常自然流暢,幾乎看不出任何人工編輯的痕跡。而且可以根據需求定制模型和微調參數,以獲得更個性化的面部替換效果。
VisoMaster 2025 最新版 1.6:超简单换脸教程,一学就会!

VisoMaster 是一個功能強大的面部替換與編輯工具,無論是靜態圖片還是動態影片,都能夠輕鬆地進行面部替換。替換後的結果非常自然流暢,幾乎看不出任何人工編輯的痕跡。而且可以根據需求定制模型和微調參數,以獲得更個性化的面部替換效果。
OpenAI 正式宣佈將會在它們的產品 ChatGPT 與及桌面應用程式中添加 Anthropic 的上下文協議 (MCP) 的支援。 OpenAI CEO Sam Altman 表示 “我們很開心能夠在我們的產品中增加對 MCP 的支持”。

Qwen 2.5-Omni,是一個由阿里巴巴團隊開發的端對端多模態模型。它的主要目的是統一處理輸入的文字、圖像、音訊和影片,能同時生成文字和自然語音作為回應。模型在多模態輸入的感知、文字與語音的同步生成以及串流處理的優化等方面都採用了創新技術同埋架構,例如 TMRoPE 時間對齊編碼和 Thinker-Talker 架構。下面的影片詳細示範了 Qwen 在不同的應用場景下的優秀表現。


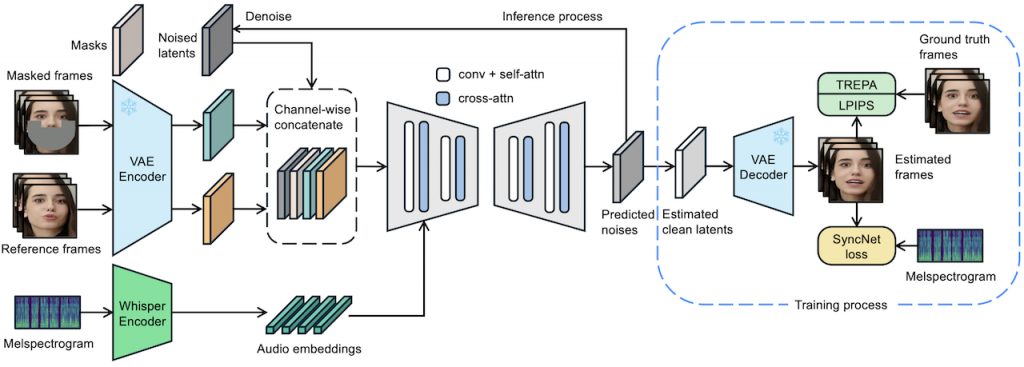
LatentSync 1.5 是 ByteDance 團隊在 GitHub 上發佈的開源專案。1.5 版本增強了中文影片的表現。它的主要功能是直接地將音頻資訊轉換成為逼真的口型動作。專案提供了完整的訓練和推論程式碼,包含資料處理流程、兩種模型訓練步驟(U-Net 和 SyncNet),以及詳細的推論指令。


MCP (Model Context Protocol) 是一種由 Anthropic 開發的開放協定,它可以令到 AI 系統能夠安全地連接各種外部資料來源進行互動,甚至製作自動化流程。 mcp.so 是一個由社群驅動的目錄,收集並整理了眾多第三方開發的 MCP 伺服器,方便用家尋找、分享和了解這些擴展 AI 功能的工具。這些 MCP 伺服器和客戶程式,涵蓋了網頁瀏覽、地圖服務、3D 建模、資料庫存取等多種應用,展現了 MCP 生態系統的豐富潛力。

HeyGem AI,一個能夠在 Windows 系統上可以離線執行的數字人合成工具。這個工具的核心功能是可以精確地複製人物外貌和聲音,創造出獨特的數字人,你可以選擇透過文字,或者語音驅動這些虛擬數字人生成影片。HeyGem AI 只是開源了前端的介面,核心技術和模型就並未公開。影片亦提供了詳細的安裝步驟、以及開放 API 的接口使用方法。


FlashVideo 由香港大學、香港科技大學及 ByteDance 聯合開發,你只需要準備一張或者幾張參考圖片,加上文字提示詞,就可以生成高解像度的影片。過程主要分為兩部份,第一部分是優先處理提示詞,同時以低解像度處理圖片,減少 DIT 的運算時間。第二部分會建立低解像度和高解像度之間的匹配。結果能夠以高速生成 1 0 8 0 P 的高清影片。[DiT] Diffusion Transformer | [NFE ] Number of Function Evaluations

NotaGen 針對160 萬首樂曲進行了訓練,亦根據高品質古典樂譜數據進行了微調。當中包括 8 千 948 張古典樂譜、152 位作曲家,並規劃成為巴洛克、古典及浪漫等三個時期。NotaGen 採用 CLaMP-DPO 強化學習,無需經過人工註釋甚至預先定義的獎勵。結果可以輕易生成非常出色的 Full Score 樂章節同埋五線譜樂章。

相關函式庫:DCML 語料庫、OpenScore 弦樂四重奏語料庫、OpenScore 歌曲語料庫、
ATEPP、KernScores

Stability AI 最新發佈的研究預覽模型「Stable Virtual Camera」是一個創新的多視角擴散模型,無需複雜的 3D 建模,就能夠將 2D 圖像轉換成為具有真實深度和透視感的沉浸式 3D 影片。同時,它亦提供了靈活的 3D 攝影機控制,用家可以自定攝影軌跡,而預設的 14 種動態攝影機路徑包括 360°、雙紐線、螺旋、移動推拉、平移和滾動等等。並且能夠由一張或者最多 32 張的圖片生成長達 1000 frames 的連貫影片。這模型目前以非商業授權,主要作為學術研究。而相關的論文、模型權重和程式碼都已經公開下載。其它 Stability 3D 模型
MedRAX 是個專為胸部 X 光影像 (俗稱肺片) 所設計的醫療推理 Agent。它的主要功能是將 X 光分析工具 C X R,以多模態整合成為一個統一的模型框架,它可以處理複雜的醫療查詢而無需要額外的訓練。為了驗證它的能力,開發團隊透過一個名為 Chest Agent Bench 的綜合評估基準測試,包括 7 個不同類別的 2,500 個醫療查詢。而最終實驗結果顯示 Med RAX 在性能上超越了同類型的模型。
