Google NotebookLM 內容創作示範 A.I. Essential for educators - 智能教育 by Google NotebookLMWatch this video on YouTube
F5-TTS 文字轉語音仿真模型 示範範例: https://SWivid.github.io/F5-TTS GitHub – SWivid/F5-TTS: 100K 小時多語言資料集上進行訓練表現出高度自然和富有表現力的零樣本能力、無縫代碼切換能力和速度控制效率。 F5-TTS (Best ElevenLabs Alternative Yet!): Easy Step-by-Step Installation + DemoWatch this video on YouTube
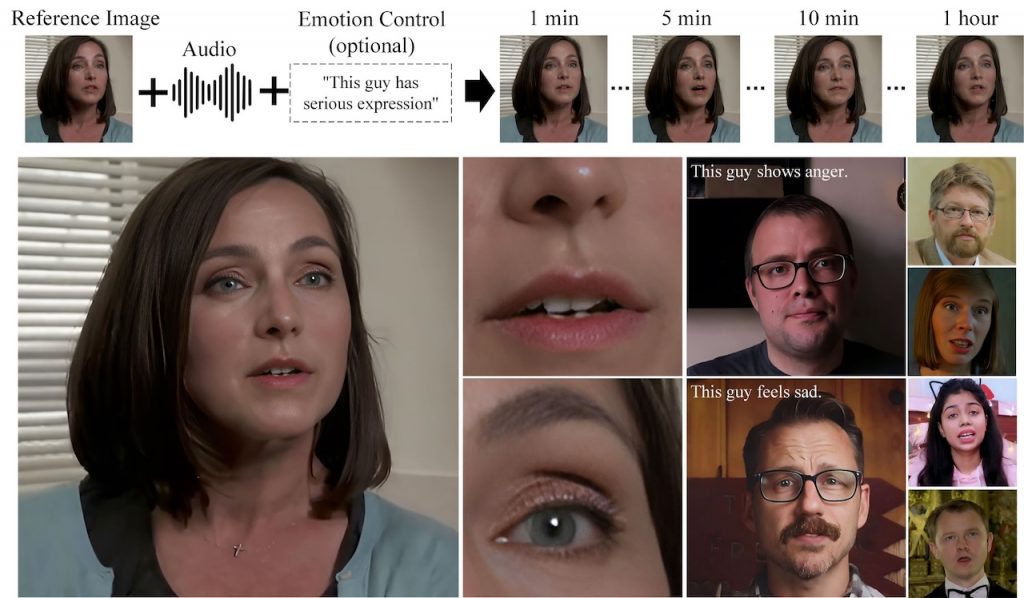
Hello2 – 高清 LipSync 工具 GitHub – fudan-generative-vision/hallo2: Hallo2: Long-Duration and High-Resolution Audio-driven Portrait Image AnimationHallo2: Long-Duration and High-Resolution Audio-driven Portrait Image Animation – fudan-generative-vision/hallo2
RF-Inversion – 無需 ControlNet 的圖片編輯 GitHub – LituRout/RF-Inversion: Rectified Flow Inversion (RF-Inversion)(附 ComfyUI Node)Rectified Flow Inversion (RF-Inversion). Contribute to LituRout/RF-Inversion development by creating an account on GitHub.
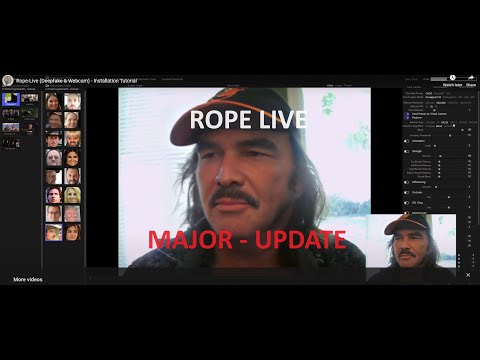
Rope-Live 具即時串流並支援 Deepfacelive 模型 Customized fork of Rope Deepfake software featuring live streaming capabilities and support for Deepfacelive models – argenspin/Rope-Live Rope-Live - Major Update & TutorialWatch this video on YouTube
diffusers-image-outpaint 零度解說 超強AI擴圖!完全免費開源,diffusers-image-outpaint,附詳細本地安裝教程!-Diffusers Image Outpaint 是一種基於擴散模型的圖像生成方法。它根據現有圖像內容,生成圖像以外區域,使圖像看起來更自然和完整。
Autoarena – LLM 效能排行 對 LLM、RAG 設定和提示的輸出進行排名,以找到系統的最佳配置使用自動一對一評估對法學碩士、RAG 系統和提示進行排名 – kolenaIO/autoarena