Phantom 是字節跳動最新的影片生成框架,主要是可以生成主體一致性(Subject-to-Video)的影片 。Phantom 會嚴格保留由用家提供的參考影像特徵,同時亦會根據提供的提示詞,創造出生動同連貫的影片。這個技術不單止可以用於單一主體,亦能夠同時處理多個主體之間的互動。透過跨模態對齊的訓練方式,Phantom 確保生成的影片內容既符合文字指令,亦能夠精準呈現參考影像中的主體。

Phantom 是字節跳動最新的影片生成框架,主要是可以生成主體一致性(Subject-to-Video)的影片 。Phantom 會嚴格保留由用家提供的參考影像特徵,同時亦會根據提供的提示詞,創造出生動同連貫的影片。這個技術不單止可以用於單一主體,亦能夠同時處理多個主體之間的互動。透過跨模態對齊的訓練方式,Phantom 確保生成的影片內容既符合文字指令,亦能夠精準呈現參考影像中的主體。
wp-ai-chat 是個開源的 WordPress 插件,旨在為 WordPress 網站整合 AI 助手功能。這個插件可以連接多種不同的 AI 模型,包括 DeepSeek、豆包、通義千問、OpenAI、Kimi 和千帆等,提供聊天、文章翻譯和 AI 生成 PPT 等功能。
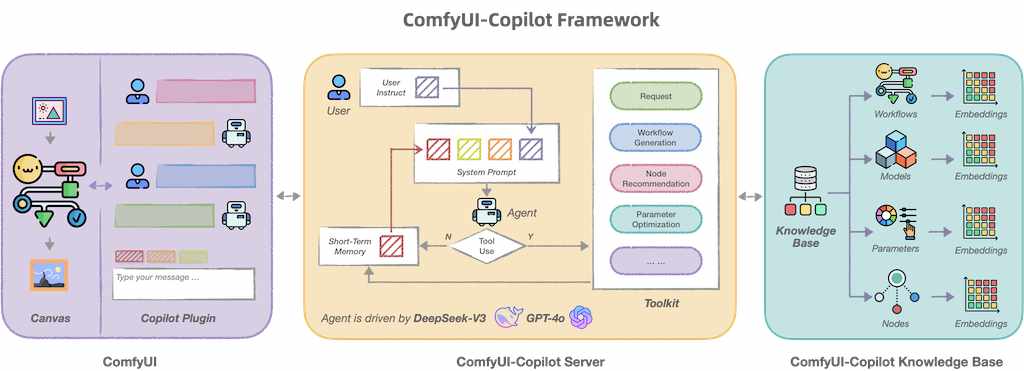
ComfyUI-Copilot 是基於 ComfyUI 框架構建的智能助手,通過自然語言交互簡化並增強 AI 算法調試和部署過程。無論是生成文本、圖像還是音頻,ComfyUI-Copilot 都提供直觀的節點推薦、工作流構建輔助和模型查詢服務,以簡化您的開發過程。
DeepSeek 開放源碼週(Open Source Week)是由中國人工智能初創公司 DeepSeek 在 2025 年 2 月 24 日至 2 月 28 日舉辦的一項活動,旨在展示它的建構開放、同埋協作性 AI 生態系統的承諾。在此期間,DeepSeek 每天發布一個開源代碼庫,總共有五個,這些代碼庫已在實際環境中得到驗證並已經開始應用於線上服務。

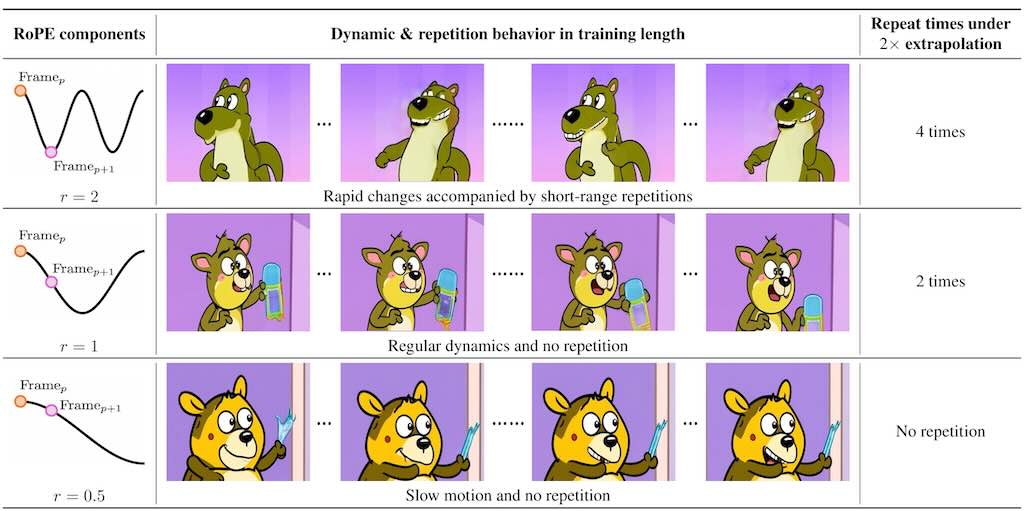
RIFLEx 主要延長影片的長度而無需重新訓練模型。研究發現,影片中不同頻率組成的部分會影響影片連貫性。在高頻會導致畫面重複,而低頻就會導致影片變成慢動作。RIFLEx 的方法是通過降低影片內在頻率,避免延長時候的重複問題,實現高品質的影片長度伸延。甚至能夠同時進行時間和空間的擴展。

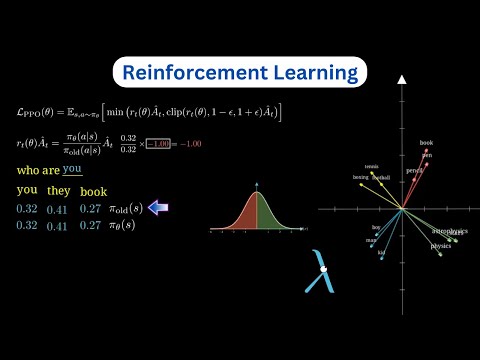
影片主要講解 DeepSeek R1 模型背後的強化學習演算法,並著重於如何透過人類回饋來訓練獎勵模型。包括如何根據人類對不同回應的偏好來調整獎勵值。接著深入探討 “近端策略優化”(Proximal Policy Optimization)演算法的細節。同時亦探討如何利用 “優勢函數”(Advantage Function)避免偏離原始策略。最後,影片亦解釋了如何運用群體策略優化成高於平均水準的回應,同時亦阻止了低於平均水準的回應,而因此提升了模型的推理能力。