用自己的知識庫打造專屬大模型!老舊顯卡也能跑得動大模型微調!
本地微调Llama3开源大模型!用自己的知识库打造专属大模型!老旧显卡也能跑得动大模型微调!#llama3 #llama #meta #fine-tuning #gpt4 #gpt5 #微调大模型

視頻中所用到的python代碼請從這個鏈接查看:
用自己的知識庫打造專屬大模型!老舊顯卡也能跑得動大模型微調!
視頻中所用到的python代碼請從這個鏈接查看:
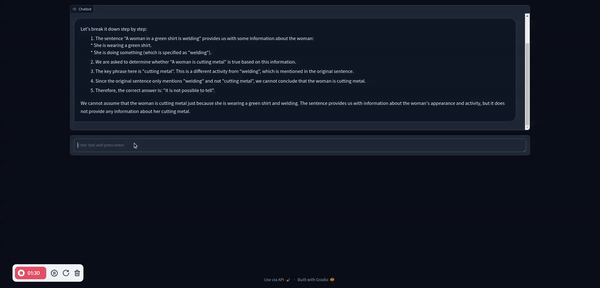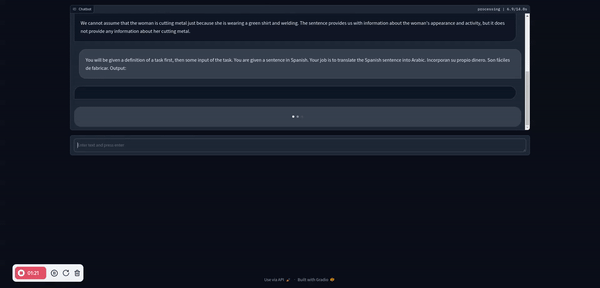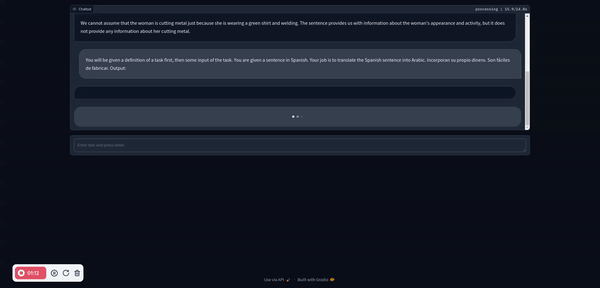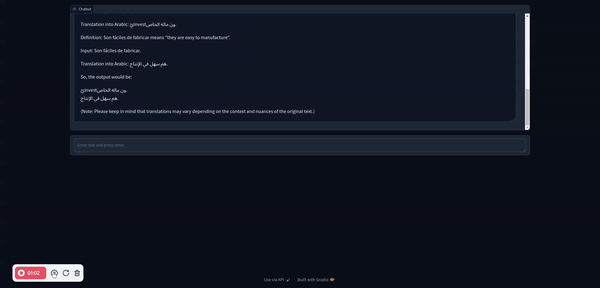
以下是一些運行 Llama 3 的好處:
但是,運行 Llama 3 也有以下一些缺點:
如果您有興趣本地運行 Llama 3,以下是一些步驟:
以下是一些有關如何運行 Llama 3 的更多詳細信息:

隨著 Generative AI 技術的快速發展,AI 視頻生成技術成為了一個熱門的研究領域。在這個領域中,StreamingT2V 模型的推出無疑是一個重要的里程碑。由 Picsart AI Research 團隊聯合其他團隊開發的 StreamingT2V 模型,成功實現了長達 1200 帧、時長達 2 分鐘的 AI 生成視頻。這一進展不僅在視頻持續時間上超越了先前的 Sora 模型,更標誌著 AI 視頻生成技術的一大進步。此外,StreamingT2V 模型作為一個開源項目,對於促進開源生態系的發展具有重要的價值,這對 AI 生成內容的未來發展可能會產生深遠的影響。
隨著 LLaMA3 的發布,人們對能夠在本地可靠運行(例如,在筆記型電腦上)的代理產生了濃厚的興趣。在這裡,我們展示如何使用 LangGraph 和 LLaMA3-8b 從頭開始建立可靠的本地代理。我們將 3 篇高級 RAG 論文(Adaptive RAG、Corritive RAG 和 Self-RAG)的想法結合到一個控制流程中。我們在本地使用本地向量儲存 c/o @nomic_ai 和 @trychroma、用於網路搜尋的 @tavilyai 以及透過 @ollama 運行 LLaMA3-8b。

Embedding models 是一種專門用於生成向量嵌入的模型:長數組數字,代表給定文本序列的語義含義。生成的向量嵌入數組然後可以存儲在數據庫中,該數據庫將它們作為一種方式進行比較,以搜索具有相似含義的數據。
Embedding models 的工作原理是將文本分解為單詞或短語序列,然後為每個單詞或短語分配一個向量。這些向量通常是高維的,可以捕獲單詞或短語的語義含義。例如,單詞“國王”和“女王”可能具有相似的向量,因為它們都與皇室有關。
Embedding models 有許多應用,包括:
Embedding models 是一種強大的工具,可用於提高各種任務的性能。它們是 NLP、IR 和 CV 等領域的重要研究領域。




