影片教你如何建立一個簡單的 Web 應用程式,使用 Ollama LangChain 和 Gradio,透過檢索增強生成 (RAG) 來查詢 PDF 文件。無論你是 AI 的初學者或已有經驗,只要有興趣用 Web 運行 AI 模型,這教學都非常實用。由於支持離線運作,因此能夠增加安全性,保障私隱,特別是對於使用 AI 處理公司內部文件嘅任務。
Run DeepSeek R1 Locally With Ollama | Build a Local Gradio App for RAG

影片教你如何建立一個簡單的 Web 應用程式,使用 Ollama LangChain 和 Gradio,透過檢索增強生成 (RAG) 來查詢 PDF 文件。無論你是 AI 的初學者或已有經驗,只要有興趣用 Web 運行 AI 模型,這教學都非常實用。由於支持離線運作,因此能夠增加安全性,保障私隱,特別是對於使用 AI 處理公司內部文件嘅任務。
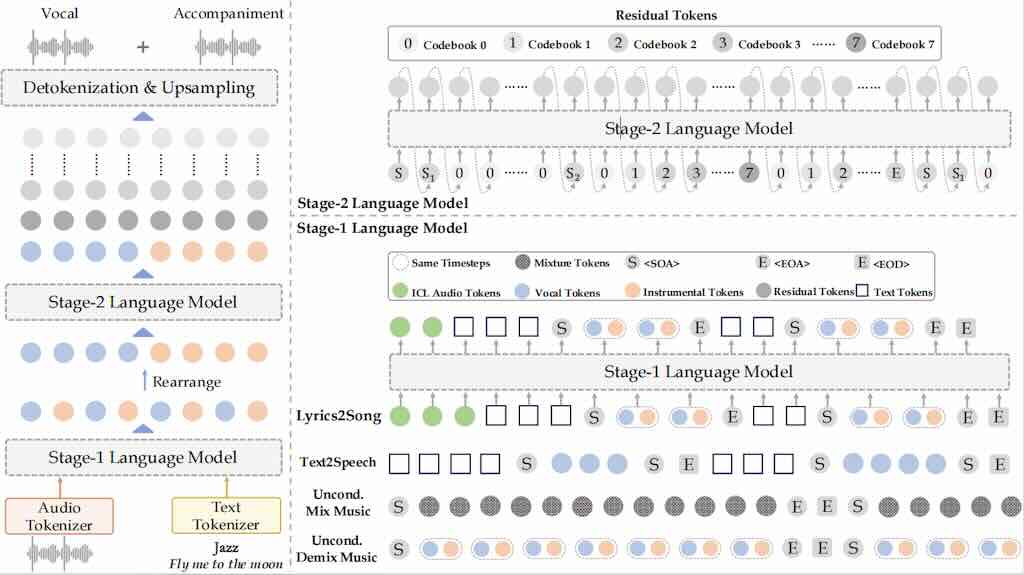
YuE 是一套開源的音樂基礎模型,專為歌詞生成完整歌曲而設計。這個名為 “lyrics2song” 的任務極具挑戰性,因為它需要處理音樂的長時序特性、音樂的複雜性、歌詞的語意,並運用語意增強的音訊雙符記技術、歌詞鏈式思考以及三階段訓練等創新方法,成功生成長達五分鐘的歌曲,並在多種音樂風格和語言中展現了令人印象深刻的結果。(支持生成塑料粵語歌)

Page Assist 是一個瀏覽器外掛,透過 Ollama 於本機運行 AI 模型,Page Assist 提供了一個十分完善的 Ollama介面。Page Assist 強調不會收集個人資料,十分注重隱私。專案是由 MIT 授權。


OpenHealth 專案是一個開源的 AI 健康助理,作者描述自己五年來花費超過十萬美元、看過三十多位醫生,卻無法確診自體免疫疾病的痛苦過程。 受到這個經歷的啟發,他開發了一個開源 AI 工具,可以幫助人們分析自己的醫療記錄,從不同的醫院提取並整理數據,並藉由 AI 模型進行分析,找出潛在的疾病。 這個工具的目的是解決醫療資訊分散的問題,讓患者能夠更全面地了解自己的健康狀況,並提供給醫生參考,但作者也強調,此工具僅為輔助診斷,不能取代專業醫療人員的判斷。

DeepSeek-VL2-small 是 DeepSeek-VL2 的小型版本,混合專家 (MoE) 視覺語言模型,旨在提升 DeepSeek-VL 的視覺效能。此模型在視覺問答、光學字元辨識和文件理解等多種任務上展現了卓越的能力。DeepSeek-VL2-small 擁有 28 億(2.8b)個參數,在效能上可與現有的其它開源模型競爭,甚至超越它們。模型的程式碼採用 MIT 許可證,模型本身的使用則受到 DeepSeek 模型許可證的約束,允許商業用途。

影片主要講解了如何使用冷啟動技術來提升小型語言模型(LLM)的推理能力,特別是在數學問題上的表現。影片的核心在於重現 DeepSeek R1 模型論文中提到的冷啟動方法,即透過少量高品質的合成數據集,讓模型在強化學習前就能夠生成清晰且連貫的思考鏈。這些數據集利用數學編譯器來產生精確的步驟式解題過程,並使用大型語言模型生成自然語言解釋,進而微調一個只有 15 億(1.5b)參數的小型模型,使其能夠進行複雜的數學推理,並在思考(think)和回答(answer)標籤中呈現其推理過程,而最終結果顯示即使是小型模型,也能透過冷啟動技術達到令人印象深刻的推理能力。影片也強調了冷啟動數據集的多樣性,包括數學、程式碼和其他領域,才能使模型具有強大的通用能力。

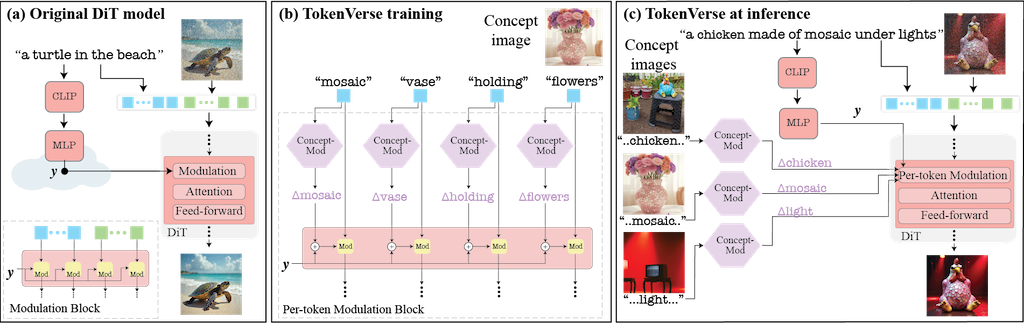
TokenVerse 提出一種基於預訓練文字轉圖像擴散模型的多概念個人化方法。它利用模型中的調製空間 (modulation space),從單張圖片中解開複雜的視覺元素和屬性,並能無縫地組合來自多張圖片的概念。不同於現有方法在概念類型或廣度上的限制,TokenVerse 能處理多張圖片的多種概念,包含物件、配件、材質、姿勢和光線等。核心方法是透過優化,為每個文字嵌入 (text embedding) 學習一個獨特的調製向量調整 (modulation vector adjustment),這些向量代表個人化的方向,可用於產生結合所需概念的新圖像。最後,論文展示了 TokenVerse 在具有挑戰性的個人化情境中的有效性,並突顯其優勢。
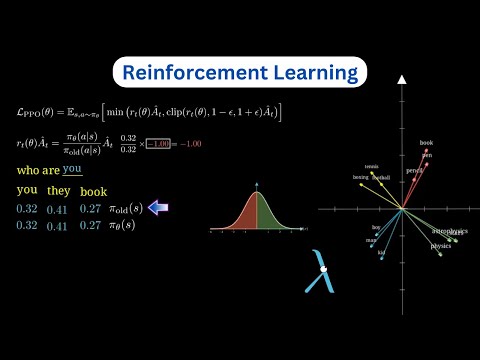
短片闡述 DeepSeek R1 模型的訓練過程,核心是基於人類回饋的強化學習。首先,短片解釋如何利用人類偏好訓練獎勵模型 (reward model):收集人類對不同模型輸出的評分,透過例如 Softmax 函數和梯階降法,調整獎勵模型,使其給予人類偏好的輸出更高分數。短片亦說明如何使用近端策略最佳化 (PPO) 演算法,結合獎勵模型和價值模型 (value model) 來微調語言模型 (policy network):根據獎勵模型給出的獎勵,以及評價模型預測的獎勵與預期差異 (advantage),調整策略網絡,使其更傾向產生高獎勵的輸出。最後,短片特別介紹 DeepSeek R1 使用的群體相對策略最佳化 (group relative policy optimization),這是一種改良的 PPO 方法,將獎勵與群體內其他輸出的平均獎勵相比,鼓勵產生優於平均水準的輸出,解決了傳統獎勵模型可能出現的「獎勵作弊」問題。
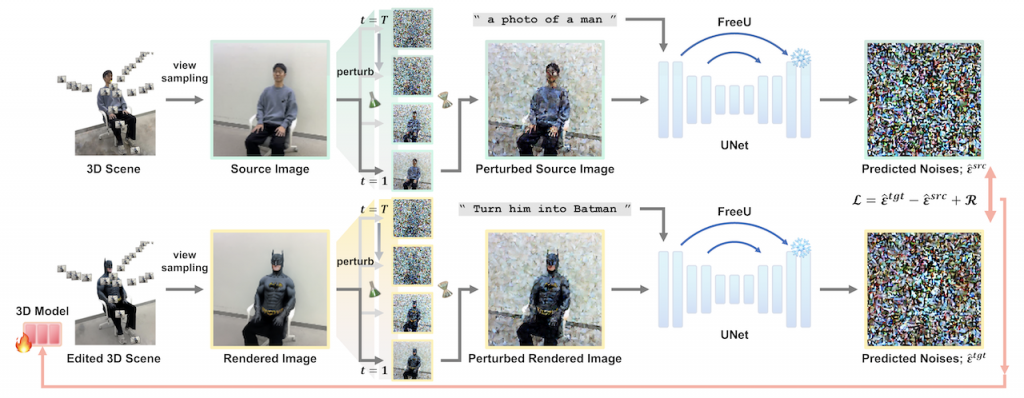
DreamCatalyst 是一個新穎的三維編輯架構,它改進了現有基於分數蒸餾採樣(SDS) 的方法,解決了訓練時間長和結果品質低的問題。DreamCatalyst 的關鍵在於將 SDS 視為三維編輯的擴散逆向過程,而不像現有方法那樣單純地蒸餾分數函數,使得更好地與擴散模型的採樣動態相協調。結果,DreamCatalyst 大幅縮短了訓練時間,並提升編輯品質,在速度和品質上都超越現有最先進的神經輻射場(NeRF) 和三維高斯散點(3DGS) 編輯方法,展現其快速且高品質的三維編輯能力。