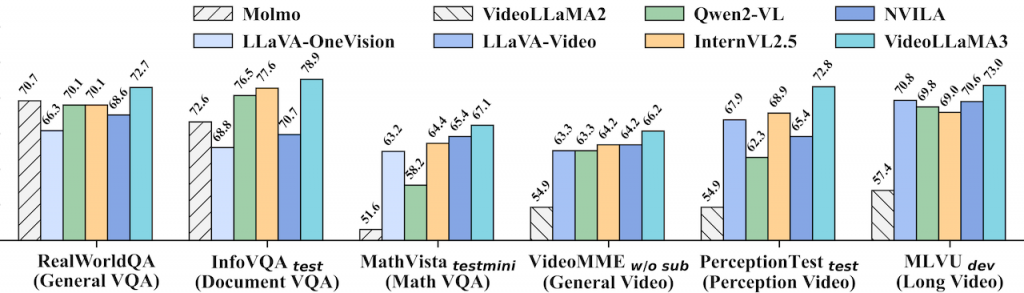
作者進行五個關於 DeepSeek R1 以及其他模型(Claude 3.5、OpenAI)的實驗。
實驗一測試模型生成 3D 瀏覽器模擬程式碼的能力,結果 DeepSeek R1 成功完成;
實驗二結合 Claude 的功能與 DeepSeek R1 的推理機制,實現更複雜的資訊處理;
實驗三探討模型在一個數值猜測遊戲中的推理過程,展現了模型的思考步驟;
實驗四修改經典的河渡問題,測試模型是否能跳脫既有訓練資料的限制,DeepSeek R1和Claude成功解決,OpenAI則失敗;
實驗五則以情境題測試模型的連續推理能力,多個模型皆能得出正確結論。
整體而言,影片旨在展示大型語言模型的程式碼生成、工具使用、推理能力以及突破訓練資料限制的潛力,並分享作者對模型能力的觀察與思考。
I Did 5 DeepSeek-R1 Experiments | Better Than OpenAI o1?