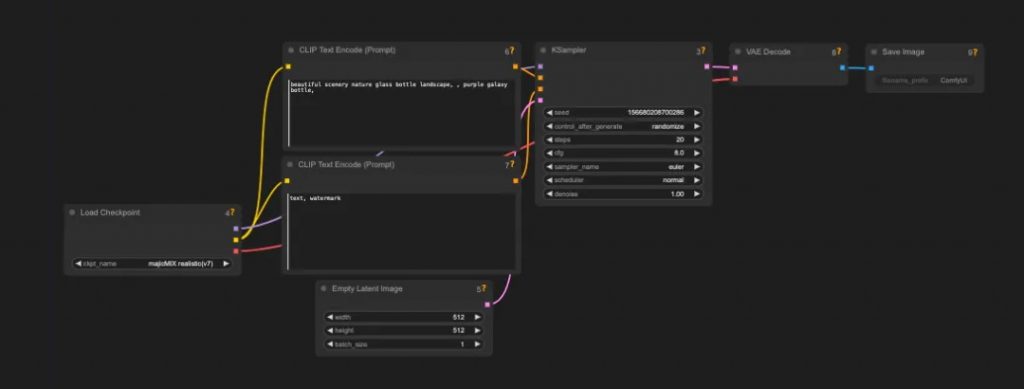
Flux 1 Dev With Realism Lora Create Cinematic AI Video Scenes – 教程 Flux 1 Dev With Realism Lora Create Cinematic AI Video Scenes - Tutorial Guide Watch this video on YouTube
SmolLM – 全開源模型 – 速度極快且功能強大 透過開源和開放科學來推進人工智慧並使之民主化模型在各種基準、測試常識推理和世界知識的規模類別中均優於其他模型 數據集包括 3000 萬份教科書、部落格文章及故事組成。
GraphRAG 提升全面性和多样性 智能問答系統:GraphRAG 能夠提高智能問答系統的準確性,提供多樣化的答案選項,大幅提升用戶體驗。 自動文本摘要:GraphRAG 能夠實現高效、準確的摘要生成,捕捉文本核心觀點,生成簡潔的摘要。 知識管理:GraphRAG 將成為企業和研究机构的重要工具,幫助構建企業級知識圖譜,提升内部知識資源管理和利用效率。 (英)Welcome to GraphRAG👉 Microsoft Research Blog Post 👉 GraphRAG Accelerator 👉 GitHub Repository 👉 GraphRAG Arxiv
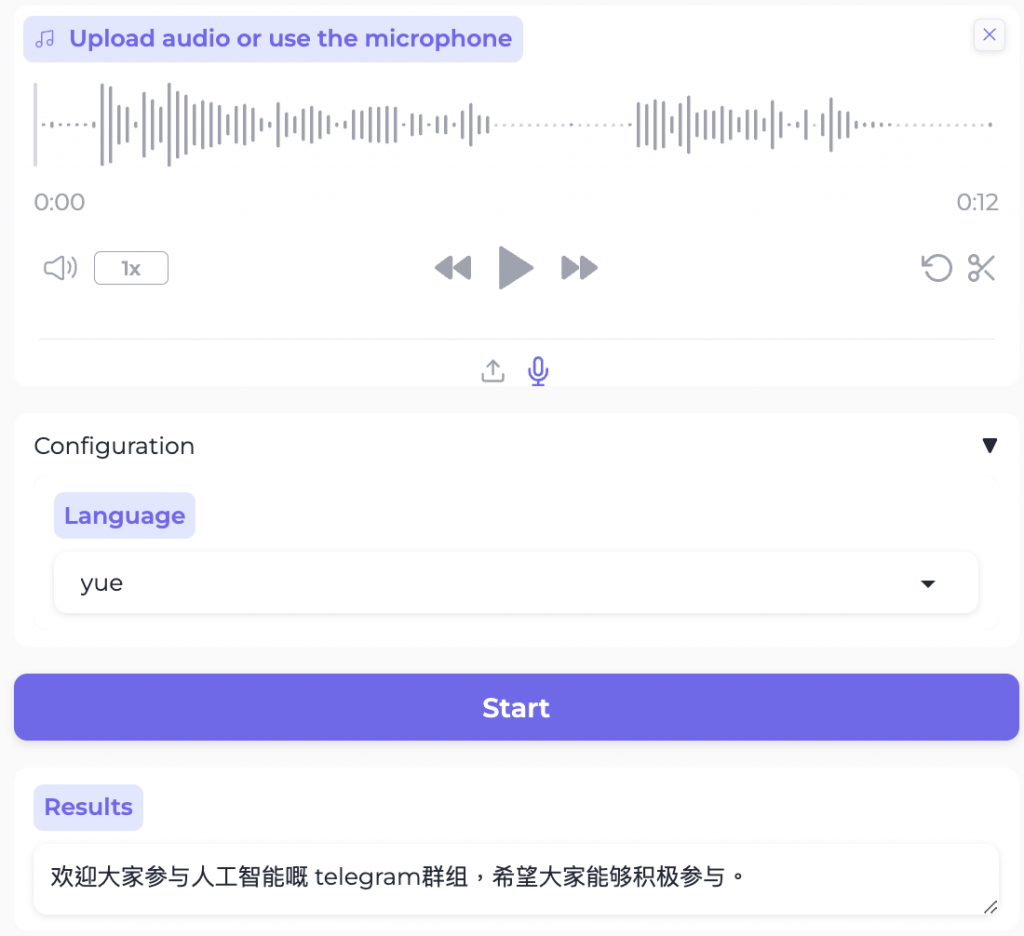
SenseVoice 具有音頻理解能力的音頻基礎模型 語音識別(ASR)、語種識別(LID)、語音情感識別(SER)和聲學事件分類(AEC)或聲學事件檢測(AED)在多個任務測試集上的benchmark,以及體驗模型所需的環境安裝的與推理方式。 Mac M1 上實測,廣東話夾英文一齊都好準,不過出嘅係簡體中文!
Llama3 RAG on Google Colab(附源碼) (英)Llama3 RAG on Google Colab使用 Llama 3、LangChain、ChromaDB 和 Gradio 建立一個檢索增強生成 (RAG) 系統。
Meta Chameleon – 多模態開源模型 (英)Meta 的 FAIR 團隊公開 Chameleon 模型於研究用Chameleon 的成功在於其完全基於 Token 的架構。模型將會同時學習圖像和文字,進行聯合推理,這對於分開編碼器的模型來說,令推理更接近 Reasoning 的要求,儘管存在一些限制。
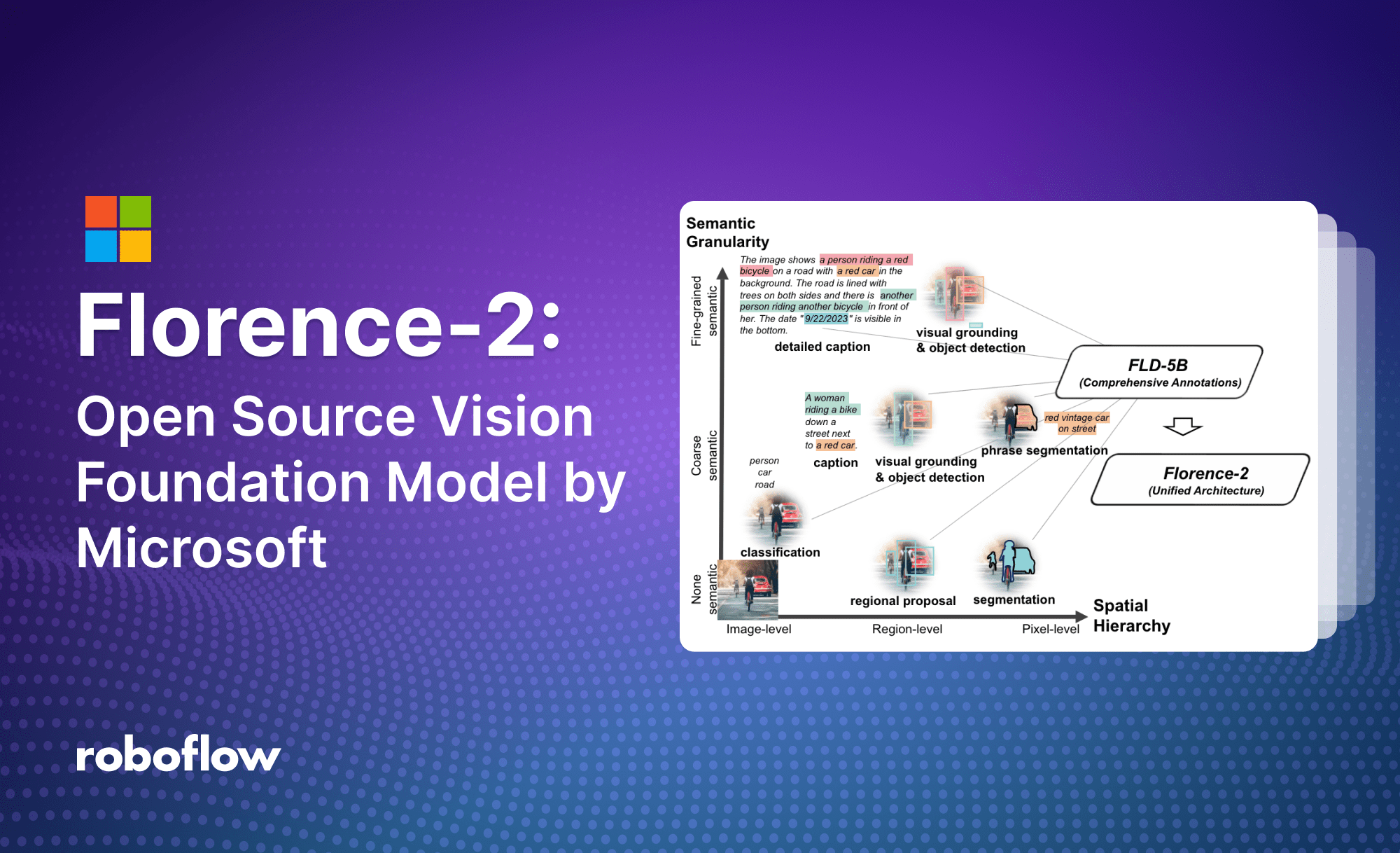
Florence-2 (Microsoft)開源模型 – 影像識別 (英)輕量級視覺語言模型模型在字幕、物件偵測、接地和分割等任務中展示了強大的零樣本和微調功能。 繼 Meta 推出多模態 open source 模型,Microsoft 也不甘後人,推出影像識別 Open source Florence-2 模型 儘管尺寸很小,但它所取得的結果與大許多倍的模型(如 Kosmos-2)相當。該模型的優勢不在於複雜的架構,而在於大規模的 FLD-5B 資料集,其中包含 1.26 億張影像和 54 億個綜合視覺註釋。
MoA : 合拼多模型 (英)MoA 允許您將多個小型模型(稱為「代理人」)组合成一個更強大的模型。透過採用每層包含多個 LLM 代理程式的分層架構,MoA 僅使用開源模型,在 AlpacaEval 2.0 上的得分為 65.1%,顯著優於 GPT-4 Omni 的 57.5%!