
Llama 3 的 10 個狂野應用範例

以下是一些 Llama 3 的具體用例:
編寫營銷文案: Llama 3 可用於生成引人入勝的營銷文案,例如產品描述、廣告標語和社交媒體帖子。
創建教育內容: Llama 3 可用於創建教育內容,例如課堂講義、測驗和練習題。
客戶服務聊天機器人: Llama 3 可用於開發客戶服務聊天機器人,這些聊天機器人可以回答客戶的問題並提供支持。
編寫創意內容: Llama 3 可用於編寫創意內容,例如詩歌、小說和腳本。
翻譯法律文件: Llama 3 可用於翻譯法律文件,例如合同和訴訟。
llama3 中文指令微調模型 Unichat-llama3-Chinese-8B · Hugging Face

Flowise 1.7.2- 開源低程式碼 LLM

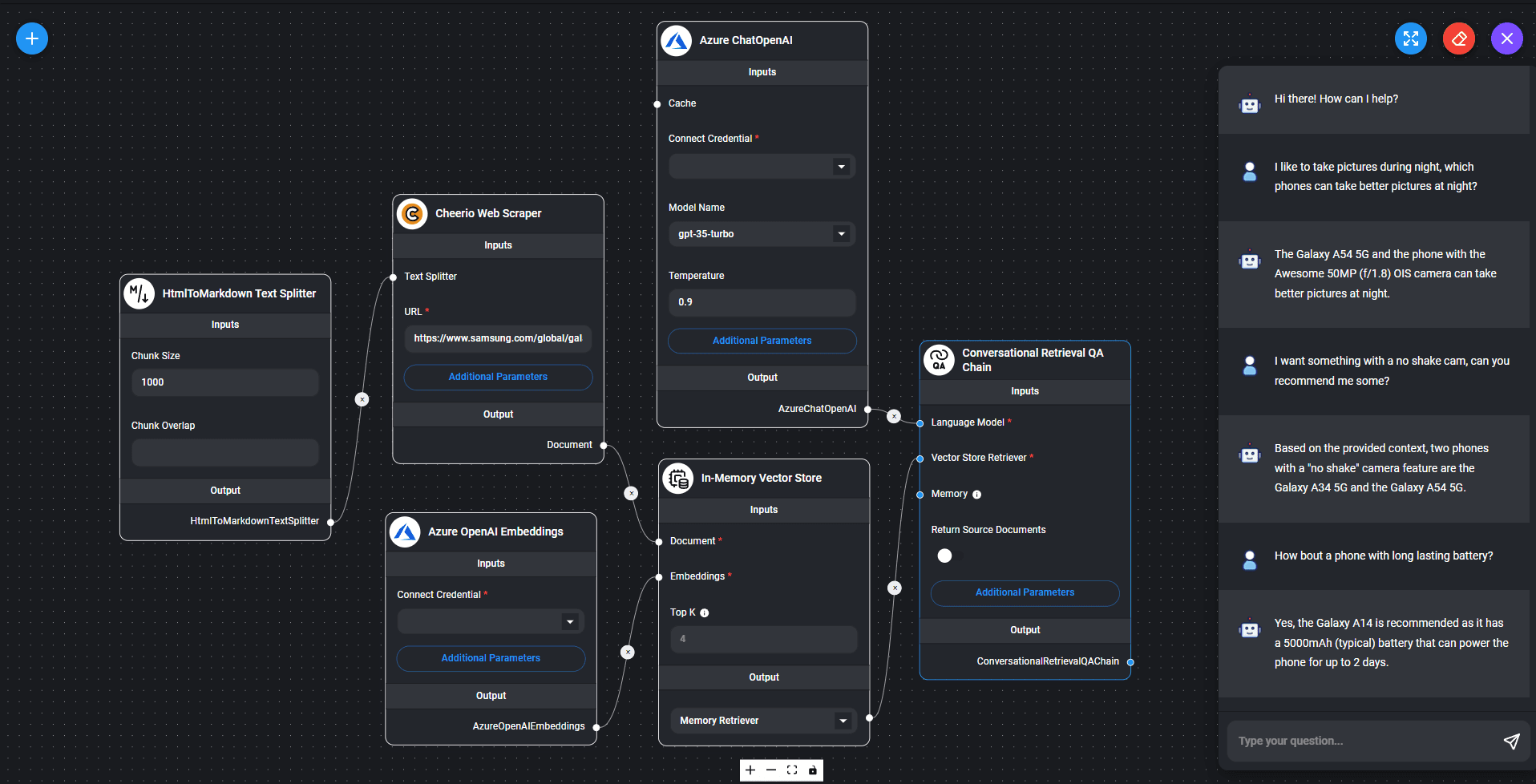
低程式碼 LLM 應用程序構建平台,允許創建和部署大型語言模型 (LLM) 的應用程序。FlowiseAI 提供一個拖放式界面,使開發人員能夠輕鬆地將 LLM 功能集成到他們的應用程序中,即使他們沒有機器學習方面的經驗。
FlowiseAI 的一些主要功能包括:
- 拖放式界面:使用的拖放式界面,允許開發人員輕鬆地創建 LLM 應用程序。
- 支持多種 LLM:支持多種 LLM,包括 OpenAI 的 GPT-3、Google AI 的 LaMDA 和 Microsoft 的 Turing NLG。
- 自定義模型:允許使用自定義模型。
- 預建應用程序:FlowiseAI 提供一系列預建應用程序,可快速入門。
- 可擴展性:可擴展到生產環境。
FlowiseAI 是個強大的工具,可用於創建各種 LLM 應用程序。它對於希望快速輕鬆地將 LLM 功能集成到其應用程序中的開發人員來說是一個很好的選擇。
以下是一些使用 FlowiseAI 創建的應用程序示例:
- 聊天機器人:創建可與用戶進行自然對話的聊天機器人。
- 虛擬助手:創建可幫助用戶完成任務的虛擬助手。
- 內容生成:用於生成創意內容,例如詩歌、代碼、腳本、音樂作品、電子郵件、信件等。
- 問答:用於創建可回答用戶問題的問答系統。
- 文本摘要:用於創建文本摘要。
parler-tts: 高品質 TTS 模型的推理和訓練庫
grok-1: Grok open release
Grok-1 是一個參數量達到 3140 億的 AI 大語言模型,其規模超越了 OpenAI GPT-3.5 的 1750 億參數,是目前世界上最大的開源 LLM 大語言模型。馬斯克通過其旗下的 AI 公司 xAI 開發了這一模型
(英)GitHub – xai-org/grok-1: Grok open release
Grok open release. Contribute to xai-org/grok-1 development by creating an account on GitHub.
馬斯克旗下的 AI 創企 xAI 在2023 年11月推出了第一代大語言模型 Grok,其中 Grok-0 是最初的版本,擁有 330 億參數。隨後,經過數次改進,推出了Grok-1。這一過程中,xAI 採用了 Mixture-of-Experts(MOE)技術,並對模型進行了持續的優化和增強。
開源時間方面,馬斯克在 2024 年 3 月 17 日正式宣佈開源 Grok-1
MobiLlama:0.5B 能在手機上運行的小型語言模型
llmware – LLM的企業級開發框架
RVC-Boss/GPT-SoVITS 語音合成模型
功能:
- 零樣本文本到語音(TTS): 輸入5秒的聲音樣本,即刻體驗文本到語音轉換。
- 少樣本TTS: 僅需1分鐘的訓練數據即可微調模型,提升聲音相似度和真實感。
- 跨語言支持: 支持與訓練數據集不同語言的推理,目前支持英語、日語和中文。
- WebUI工具: 集成工具包括聲音伴奏分離、自動訓練集分割、中文自動語音識別(ASR)和文本標注,協助初學者創建訓練數據集和GPT/SoVITS模型。
如果你是 Windows用戶(已在 win>=10上測試),可以直接通過預打包文件安裝。只需下載預打包文件,解壓後雙擊 go-webui.bat 即可啓動 GPT-SoVITS-WebUI。預訓練模型
GPT-SoVITS语音克隆AI,只需一分钟素材训练模型,效果堪比商用。一键安装,附Colab脚本 | TTS | RVC|GPT-SoVITS Colab

從 GPT-SoVITS Models 下載預訓練模型,並將它們放置在 GPT_SoVITS\pretrained_models 中。
對於中文自動語音識別(另外),從 Damo ASR Model, Damo VAD Model, 和 Damo Punc Model 下載模型,並將它們放置在 tools/damo_asr/models 中。
對於UVR5(人聲/伴奏分離和混響移除,另外),從 UVR5 Weights 下載模型,並將它們放置在 tools/uvr5/uvr5_weights 中。
數據集格式
文本到語音(TTS)注釋 .list 文件格式:
vocal_path|speaker_name|language|text
語言字典:
- ‘zh’: Chinese
- ‘ja’: Japanese
- ‘en’: English
示例:
D:\GPT-SoVITS\xxx/xxx.wav|xxx|en|I like playing Genshin.
