Google Research 發佈 TimesFM,這是一個基於 Transformer 的 200M 參數基礎模型,用於時間序列預測。 TimesFM 經過近 100B 個資料點的訓練,具有零樣本預測效能
這個 預訓練時間序列基礎模型(Time Series Foundation Model),可用於時間序列預測。它是一種基於 Transformer 的模型,在大量時間序列數據上進行了預訓練。TimesFM 可以用於各種時間序列預測任務,包括:
- 銷售預測
- 庫存管理
- 需求預測
- 異常檢測
- 設備故障預測
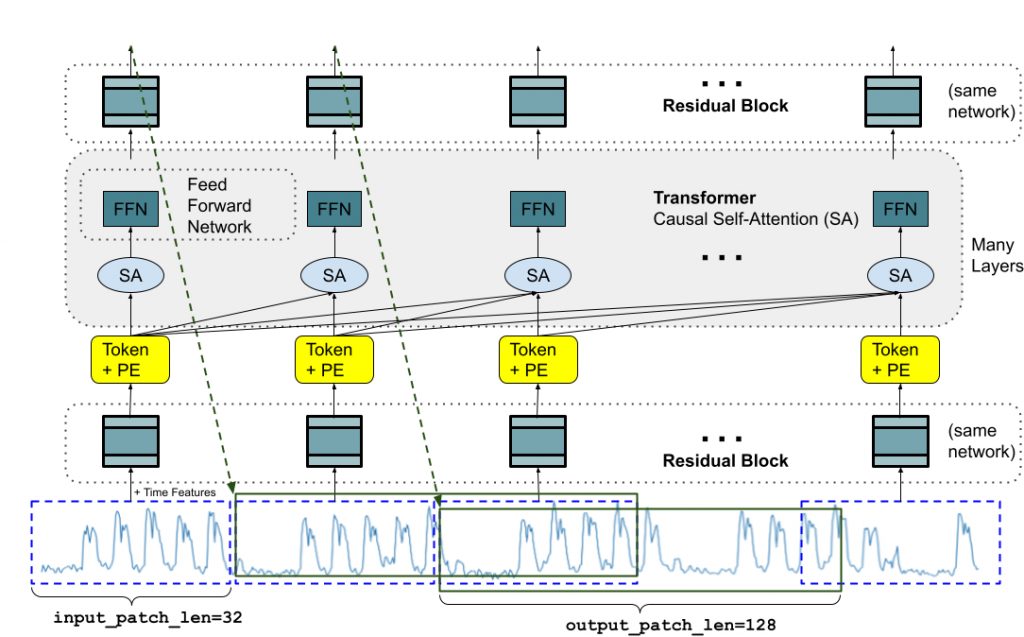
TimesFM 是由 Google Research 開發的預訓練時間序列基礎模型(Time Series Foundation Model),可用於時間序列預測。它是一種基於 Transformer 的模型,在大量時間序列數據上進行了預訓練。TimesFM 可以用於各種時間序列預測任務,包括:
- 銷售預測
- 庫存管理
- 需求預測
- 異常檢測
- 設備故障預測
TimesFM 的優點包括:
- **高準確性:**TimesFM 在許多基準測試中表現出最先進的準確性。
- **可解釋性:**TimesFM 可以提供其預測的解釋,這有助於用戶理解模型的決策。
- **可擴展性:**TimesFM 可以針對各種時間序列預測任務進行微調。
TimesFM 的工作原理是學習時間序列數據的表示。然後,它可以使用此表示來預測新數據點的值。TimesFM 使用的一種特殊技術稱為自注意力(self-attention)。自注意力允許模型學習序列中不同點之間的長期依賴關係。
TimesFM 已被用於各種應用,包括:
- **零售:**TimesFM 可用於預測零售產品的銷售額。這有助於零售商優化其庫存水平和促銷活動。
- **金融:**TimesFM 可用於預測股票價格和匯率。這有助於金融機構做出明智的投資決策。
- **製造業:**TimesFM 可用於預測機器故障。這有助於製造商防止停機和生產損失。
TimesFM 是一種強大的工具,可用於各種時間序列預測任務。它有可能在許多行業產生重大影響。
以下是一些關於 TimesFM 的其他資源:





