一個以視覺為中心的多模態基礎模型,用於圖像和影片理解。其核心設計理念是優先利用高品質的圖像文字數據,而非大規模的影片文字數據進行訓練。模型採用四階段訓練流程:視覺對齊、視覺語言預訓練、多任務微調以及影片中心微調。此外,VideoLLaMA3 的架構設計能根據影像大小動態調整視覺 token 數量,並在影片處理中減少冗餘的視覺 token,以提升效率和準確性。最終,VideoLLaMA3 在圖像和影片理解基準測試中取得了令人信服的成果。(HuggingFace)
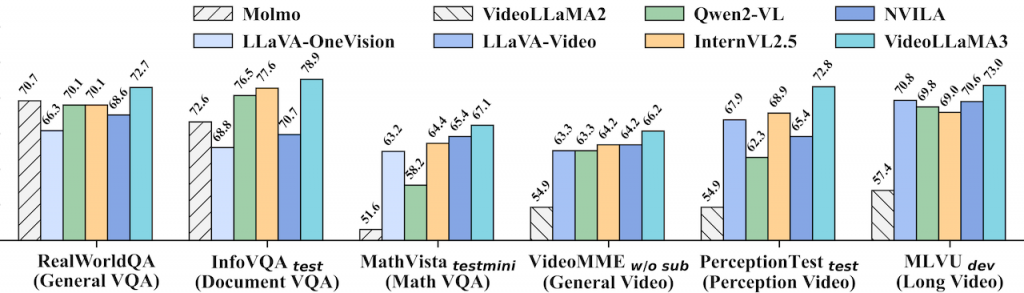
一個以視覺為中心的多模態基礎模型,用於圖像和影片理解。其核心設計理念是優先利用高品質的圖像文字數據,而非大規模的影片文字數據進行訓練。模型採用四階段訓練流程:視覺對齊、視覺語言預訓練、多任務微調以及影片中心微調。此外,VideoLLaMA3 的架構設計能根據影像大小動態調整視覺 token 數量,並在影片處理中減少冗餘的視覺 token,以提升效率和準確性。最終,VideoLLaMA3 在圖像和影片理解基準測試中取得了令人信服的成果。(HuggingFace)